After we have considered how the ARM32 kernel uncompressed and the early start-up when the kernel jumps from executing in physical memory to executing in virtual memory we now want to see what happens next all the way until the kernel sets up the proper page tables and starts executing from properly paged virtual memory.
To provide a specific piece of the story that does not fit into this linear explanation of things, i have also posted a separate article on how the ARM32 page tables work. This will be referenced in the text where you might need to recapture that part.
To repeat: we have a rough initial section mapping of 1 MB sections covering the kernel RAM and the provided or attached Device Tree Blob (DTB) or ATAGs if we use a legacy system that is not yet using device tree. We have started executing from virtual memory in arch/arm/kernel/head-common.S, from the symbol __mmap_switched where we set up the C runtime environment and jump to start_kernel() in init/main.c. The page table is at a pointer named swapper_pg_dir.
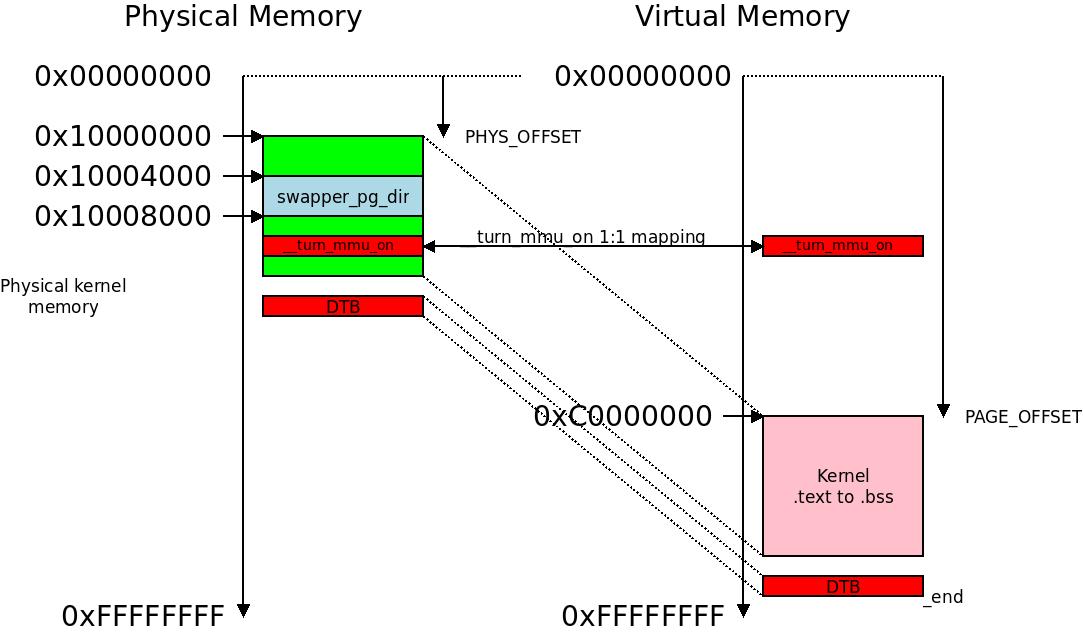 The initial page table
The initial page table swapper_pg_dir and the 1:1 mapped one-page-section __turn_mmu_on alongside the physical to virtual memory mapping at early boot. In this example we are not using LPAE so the initial page table is -0x4000 from (PAGE_OFFSET +TEXT_OFFSET), usually at 0xC0004000 thru 0xC0007FFF and memory ends at 0xFFFFFFFF.
We are executing in virtual memory, but interrupts and caches are disabled and absolutely no device drivers are available, except the initial debug console. The initial debug console can be enabled with CONFIG_DEBUG_LL and selecting the appropriate debug UART driver for your system. This makes the kernel completely non-generic and custom for your system but is great if you need to debug before the device drivers come up. We discussed how you can insert a simple print in start_kernel() using this facility.
In the following text we start at start_kernel() and move down the setup_arch() call. When the article ends, we are not yet finished with setup_arch() so there will be a second part to how we set up the architecture. (I admit I ran over the maximum size for a post, else it would be one gigantic post.)
In the following I will not discuss the “nommu” (uClinux) set-up where we do not use virtual memory, but just a 1-to-1 physical-to-virtual map with cache and memory protection. It is certainly an interesting case, but should be the topic for a separate discussion. We will describe setting up Linux on ARM32 with full classic or LPAE MMU support.
Setting Up the Stack Pointer and Memory for the init Task
In the following section the words task and thread are used to indicate the same thing: an execution context of a process, in this case the init process.
Before we start executing in virtual memory we need to figure out where our stack pointer is set. __mmap_switched in head-common.S also initializes the ARM stack pointer:
ARM( ldmia r4!, {r0, r1, sp} )
THUMB( ldmia r4!, {r0, r1, r3} )
THUMB( mov sp, r3 )
r4 in this case contains __mmap_switched_data where the third variable is:
.long init_thread_union + THREAD_START_SP
THREAD_START_SP is defined as (THREAD_SIZE - 8), so 8 bytes backward from the end of the THREAD_SIZE number of bytes forward from the pointer stored in the init_thread_union variable. This is the first word on the stack that the stack will use, which means that bytes at offset THREAD_SIZE - 8, -7, -6, -5 will be used by the first write to the stack: only one word (4 bytes) is actually left unused at the end of the THREAD_SIZE memory chunk.
The init_thread_union is a global kernel variable pointing to the task information for the init process. You find the actual memory for this defined in the generic linker file for the kernel in include/asm-generic/vmlinux.lds.h where it is defined as a section of size THREAD_SIZE in the INIT_TASK_DATA section definition helper. ARM32 does not do any special tricks with this and it is simply included into the RW_DATA section, which you find in the linker file for the ARM kernel in arch/arm/kernel/vmlinux.lds.S surrounded by the labels _sdata and _edata and immediately followed by the BSS section:
_sdata = .;
RW_DATA(L1_CACHE_BYTES, PAGE_SIZE, THREAD_SIZE)
_edata = .;
BSS_SECTION(0, 0, 0)
This will create a section which is aligned at a page boundary, beginning with INIT_TASK_DATA of size THREAD_SIZE, initialized to the values assigned during compilation and linking and writable by the kernel.
The union thread_union is what is actually stored in this variable, and in the ARM32 case it actually looks like this after preprocessing:
union thread_union {
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
It is just an array of unsigned long 4 byte chunks, as the word length on ARM32 is, well 32 bits, and sized so that it will fit a THREAD_SIZE stack. The name stack is deceptive: this chunk of THREAD_SIZE bytes stores all ARM-specific context information for the task, and the stack, with the stack in the tail of it. The remaining Linux generic accounting details are stored in a struct task_struct which is elsewhere in memory.
THREAD_SIZE is defined in arch/arm/include/asm/thread_info.h to be (PAGE_SIZE << THREAD_SIZE_ORDER) where PAGE_SIZE is defined in arch/arm/include/asm/page.h to be (1 << 12) which usually resolves to (1 << 13) so the THREAD_SIZE is actually 0x2000 (8196) bytes, i.e. 2 consecutive pages in memory. These 0x2000 bytes hold the ARM-specific context and the stack for the task.
The struct thread_info is the architecture-specific context for the task and for the init task this is stored in a global variable called init_thread_info that you find defined at the end of init/init_task.c:
struct thread_info init_thread_info __init_thread_info = INIT_THREAD_INFO(init_task);
The macro __init_thread_info expands to a linker directive that puts this into the .data.init_thread_info section during linking, which is defined in the INIT_TASK_DATA we just discussed, so this section is only there to hold the init task thread_info. 8 bytes from the end of this array of unsigned longs that make up the INIT_TASK_DATA is where we put the stack pointer.
Where is this init_thread_union initialized anyway?
It is pretty hard to spot actually, but the include/asm-generic/vmlinux.lds.h INIT_DATA_TASK linker macro does this. It contains these statements:
init_thread_union = .;
init_stack = .;
So the memory assigned to the pointers init_thread_union and init_stack is strictly following each other in memory. When the .stack member of init_task is assigned to init_stack during linking, it will resolve to a pointer just a little further ahead in memory, right after the memory chunk set aside for the init_thread_union. This is logical since the stack grows toward lower addresses on ARM32 systems: .stack will point to the bottom of the stack.
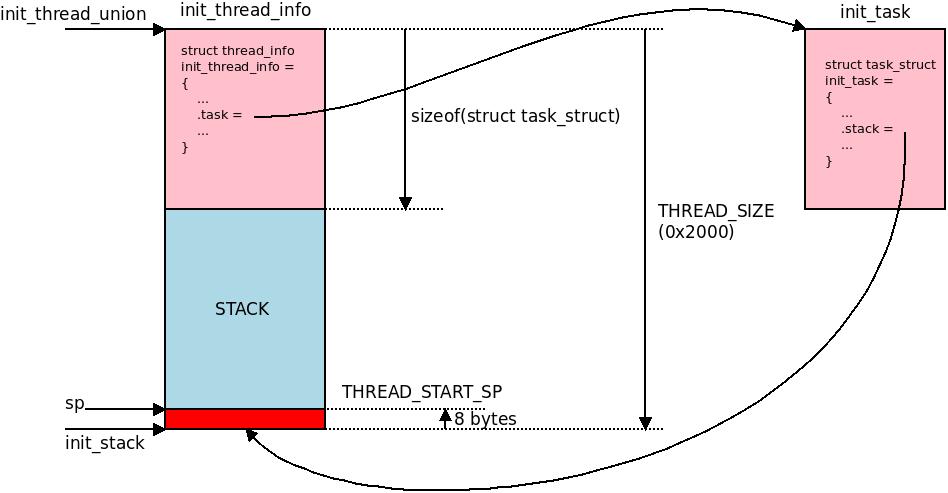 During the early start of the kernel we take extra care to fill out these two
During the early start of the kernel we take extra care to fill out these two thread_info and task_struct data structures and the pointers to different offsets inside it. Notice the sp (stack pointer) pointing 8 bytes up from the end of the end of the two pages assigned as memory to hold the task information. The first word on the stack will be written at sp, typically at offset 0x1FF8 .. 0x1FFB.
This init_stack is assigned to .stack of struct task_struct init_task in init/init_task.c, where the rest of the task information for the init task is hardcoded. This task struct for the init task is in another place than the thread_info for the init task, they just point back and forth to each other. The task_struct is the generic kernel part of the per-task information, while the struct thread_info is an ARM32-specific information container that is stored together with the stack.
Here we see how generic and architecture-specific code connect: the init_thread_info is something architecture-specific and stores the state and stack of the init task that is ARM32-specific, while the task_struct for the init task is something completely generic, all architectures use the same task_struct.
This init task is task 0. It is not identical to task 1, which will be the init process. That is a completely different task that gets forked in userspace later on. This task is only about providing context for the kernel itself, and a point for the first task (task 1) to fork from. The kernel is very dependent on context as we shall see, and that is why its thread/task information and even the stack pointer for this “task zero” is hardcoded into the kernel like this. This “zero task” does not even appear to userspace if you type ps aux, it is hidden inside the kernel.
Initializing the CPU
The very first thing the kernel does in start_kernel() is to initialize the stack of the init task with set_task_stack_end_magic(&init_task). This puts a STACK_END_MAGIC token (0x57AC6E9D) where the stack ends. Since the ARM stack grows downwards, this will be the last usable unsigned long before we hit the thread_info on the bottom of the THREAD_SIZE memory chunk associated with our init task.
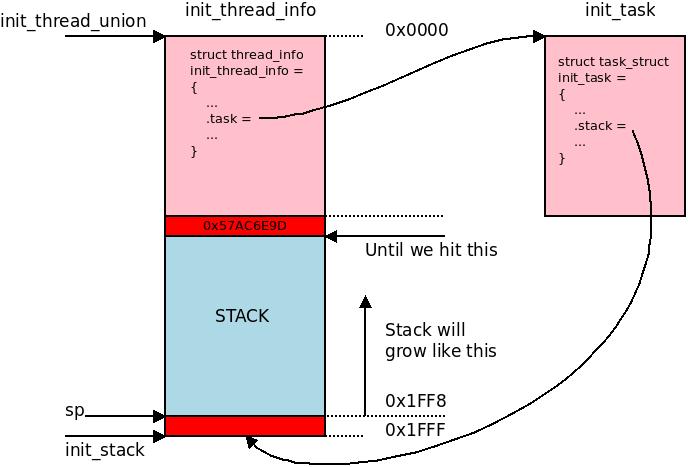 We insert a
We insert a 0x57AC6E9D token so we can see if the last word of per-task stack ever gets overwritten and corrupted. The ARM32 stack grows towards the lower addresses. (Up along the arrow in the picture.)
Next smp_setup_processor_id() is called which is a weak symbol that each architecture can override. ARM does this: arch/arm/kernel/setup.c contains this function and if we are running on an SMP system, we execute read_cpuid_mpidr() to figure out the ID of the CPU we are currently running on and initialize the cpu_logical_map() array such that the current CPU is at index 0 and we print the very first line of kernel log which will typically be something like:
Booting Linux on physical CPU 0x0
If you are running on a uniprocessor system, there will be no print like this.
The kernel then sets up some debug objects and control group information that is needed early. We then reach local_irq_disable(). Interrupts are already disabled (at least they should be) but we exercise this code anyways. local_irq_disable() is defined to arch_local_irq_disable() which in the ARM case can be found in arch/arm/include/asm/irqflags.h. As expected it resolves to the assembly instruction cpsid i which will disable any ordinary IRQ in the CPU. This is short for change processor state interrupt disable i. It is also possible to issue cpsid f to disable FIQ, which is an interrupt which the ARM operating systems seldom make use of.
ARM systems usually also have an interrupt controller: this is of no concern here: we are disabling the line from the interrupt controller (such as the GIC) to the CPU: this is the big main switch, like going down in the basement and cutting the power to an entire house. Any other lightswitches in the house are of no concern at this point, we haven’t loaded a driver for the interrupt controller so we just ignore any interrupt from any source in the system.
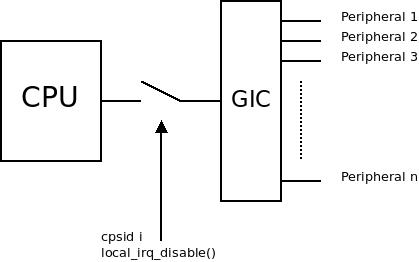 The local_irq_disable() results in cpsid i which will cut the main interrupt line to the CPU core.
The local_irq_disable() results in cpsid i which will cut the main interrupt line to the CPU core.
This move makes a lot of sense, because at this point we have not even set up the exception vectors, which is what all IRQs have to jump through to get to the destined interrupt handler. We will get to this in due time.
Next we call boot_cpu_init(). As the name says this will initialize the one and only CPU we are currently running the kernel on. Normally any other CPUs in the system are just standing by with frozen instruction counters at this point. This does some internal kernel bookkeeping. We note that smp_processor_id() is called and __boot_cpu_id is assigned in the SMP case. smp_processor_id() is assigned to raw_smp_processor_id() in include/linux/smp.h and that will go back into the architecture in arch/arm/include/asm/smp.h and reference the global variable current_thread_info()->cpu, while on uniprocessor (UP) systems it is simply defined to 0.
Let’s see where that takes us!
In the SMP case, current_thread_info() is defined in arch/arm/include/asm/thread_info.h and is dereferenced from the current_stack_pointer like this:
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)
(current_stack_pointer & ~(THREAD_SIZE - 1));
}
current_stack_pointer in turn is defined in arch/arm/include/asm/percpu.h and implemented as the assembly instruction sp. We remember that we initialized this to point at the end of THREAD_SIZE minus 8 bytes of the memory reserved for init_thread_info. The stack grows backward. This memory follows right after the thread_info for the init task so by doing this arithmetic, we get a pointer to the current struct thread_info, which will be the init_task. Further we see that the link file contains this:
. = ALIGN(THREAD_SIZE);
(...)
RW_DATA(L1_CACHE_BYTES, PAGE_SIZE, THREAD_SIZE)
So the linker takes care to put thread info into a THREAD_SIZE:d chunk in memory. This means that if THREAD_SIZE is 0x2000, then the init task thread_info will always be on addresses like 0x10000000, 0x10002000, 0x10004000...
For example if THREAD_SIZE is 0x2000 then (THREAD_SIZE - 1) is 0x00001FFF and ~0x00001FFF is 0xFFFFE000 and since we know that the struct thread_info always start on an even page, this arithmetic will give us the address of the task information from the stack pointer. If the init_thread_info ends up at 0x10002000 then sp points to 0x10003FF8 and we calculate 0x10003FF8 & 0xFFFFE000 = 0x10002000 and we have a pointer to our thread_info, which in turn has a pointer to init_task: thus we know all about our context from just using sp.
Thus sp is everything we need to keep around to quickly look up the information of the currently running task, i.e. the process context. This is a central ARM32 Linux idea.
Since the kernel is now busy booting we are dealing with the init task, task 0, but all tasks that ever get created on the system will follow the same pattern: we go into the task context and use sp to find any information associated with the task. The init_task provides context so we don't crash. Now it becomes evident why this special “task zero” is needed so early.
So to conclude: when raw_smp_processor_id() inspects current_thread_info()->cpu to figure out what CPU we are running on, this thread info is going to be the init_thread_info and ->cpu is going to be zero because the compiler has assigned the default value zero to this member during linking (we haven’t assigned anything explicitly). ->cpu is an index and at index zero in the cpu_logical_map() is where we poked in our own CPU ID a little earlier using smp_setup_processor_id() so we can now find ourselves through the sp. We have come full circle.
As I pointed out this clever sp mechanism isn’t just used for the init task. It is used for all tasks on the system, which means that any allocated thread info must strictly be on a memory boundary evenly divisible with THREAD_SIZE. This works fine because kmalloc() that is used to allocate kernel memory returns chunks that are “naturally aligned”, which means “aligned to the object size if that size is a power of two” – this will ascertain that the allocation ends up on a page boundary evenly divisible by the object allocated, and the current_thread_info() call will always work fine. This is one of the places where the kernel assumes this kind of natural alignment.
Hello World
Next we call page_address_init() which mostly does nothing, but if the system is using highmem (i.e. has a lot of memory) this will initialize a page hash table. We will explain more about how highmem is handled later in this article.
Next we print the Linux banner. The familiar first text of the kernel appear in the kernel print buffer stating what version and git hash we built from and what compiler and linker was used to build this kernel:
Linux version 5.9.0-rc1-00021-gbbe281ed6cfe-dirty (...)
Even if we have an early console defined for the system, i.e. if we defined CONFIG_DEBUG_LL these first few messages will still NOT be hammered out directly on the console. They will not appear until we have initialized the actual serial console driver much later on. Console messages from CONFIG_DEBUG_LL only come out on the console as a result of printascii() calls. This banner is just stashed aside in the printk memory buffer until we get to a point where there is a serial device that can actually output this text. If we use earlyprintk and the serial driver has the proper callbacks, it will be output slightly earlier than when the memory management is properly up and running. Otherwise you will not see this text until the serial driver actually gets probed much later in the kernel start-up process.
But since you might have enabled CONFIG_DEBUG_LL there is actually a trick to get these prints as they happen: go into kernel/printk/printk.c and in the function vprintk_store() insert some code like this at the end of the function, right before the call to log_output():
#if defined(CONFIG_ARM) && defined(CONFIG_DEBUG_LL)
{
extern void printascii(char *);
printascii(textbuf);
}
#endif
Alternatively, after kernel version v5.11-rc1:
if (dev_info)
memcpy(&r.info->dev_info, dev_info, sizeof(r.info->dev_info));
#if defined(CONFIG_ARM) && defined(CONFIG_DEBUG_LL)
{
extern void printascii(char *);
printascii(&r.text_buf[0]);
}
#endif
This will make all printk:s get hammered out on the console immediately as they happen, with the side effect that once the serial port is up you get conflict about the hardware and double prints of everything. However if the kernel grinds to a halt before that point, this hack can be really handy: even the very first prints to console comes out immediately. It’s one of the ARM32-specific hacks that can come in handy.
Next we call early_security_init() that will call ->init() on any Linux Security Modules (LSMs) that are enabled. If CONFIG_SECURITY is not enabled, this means nothing happens.
Setting Up the Architecture
The next thing that happens in start_kernel() is more interesting: we call setup_arch() passing a pointer to the command line. setup_arch() is defined in <linux/init.h> and will be implemented by each architecture as they seem fit. The architecture initializes itself and passes any command line from whatever mechanism it has to provide a command line. In the case of ARM32 this is implemented in arch/arm/kernel/setup.c and the command line can be passed from ATAGs or the device tree blob (DTB).
Everything in this article from this point on will concern what happens in setup_arch(). Indeed this function has given the name to this whole article. We will conclude the article once we return out of setup_arch(). The main focus will be memory management in the ARM32 MMUs.
Setting Up the CPU
ARM32 first sets up the processor. This section details what happens in the setup_processor() call which is the first thing the setup_arch() calls. This code will identify the CPU we are running on, determine its capabilities such as cache type and prepare the exception stacks. It will however not enable the caches or any other MMU functionality such as paging, that comes later.
We call read_cpuid_id() which in most cases results in a CP15 assembly instruction to read out the CPU ID: mrc p15, 0, <Rd>, c0, c0, 0 (some silicon such as the v7m family require special handling).
Using this ID we cross reference a struct with information about the CPU, struct proc_info_list. This is actually the implementation in assembly in head-common.S that we have seen earlier, so we know that this will retrieve information about the CPU from the files in arch/arm/mm/proc-*.S for example arch/arm/mm/proc-v7.S for all the ARMv7 processors. With some clever linkage the information about the CPU is now assigned into struct proc_info_list from arch/arm/include/asm/procinfo.h, so that any low-level information about the CPU and a whole set of architecture-specific assembly functions for the CPU can be readily accessed from there. A pointer to access these functions is set up in a global vector table named, very clearly, processor.
We print the CPU banner which can look something like this (Qualcomm APQ8060, a dual-core Cortex A9 SMP system):
CPU: ARMv7 Processor [510f02d2] revision 2 (ARMv7), cr=10c5787d
From the per-processor information struct we also set up elf_hwcap and elf_hwcap2. These flags that can be found in arch/arm/include/uapi/asm/hwcap.h tells the ELF (Executable and Linkable Format) parser in the kernel what kind of executable files we can deal with. For example if the executable is using hardware floating point operations or NEON instructions, a flag is set in the ELF header, and compared to this when we load the file so that we can determine if we can even execute the file.
Just reading that out isn’t enough though so we call in succession cpuid_init_hwcaps() to make a closer inspection of the CPU, disable execution of thumb binaries if the kernel was not compiled with thumb support, and we later also call elf_hwcap_fixup() to get these flags right for different fine-granular aspects of the CPU.
Next we check what cache type this CPU has in cacheid_init(). You will find these in arch/arm/include/asm/cachetype.h with the following funny names tagged on: VIVT, VIPT, ASID, PIPT. Naturally, this isn’t very helpful. These things are however clearly defined in Wikipedia, so go and read.
We then call cpu_init() which calls cpu_proc_init() which will execute the per-cputype callback cpu_*_proc_init from the CPU information containers in arch/arm/mm/proc-*.S. For example, the Faraday FA526 ARMv4 type CPU cpu_fa526_proc_init() in arch/arm/mm/proc-fa526.S will be executed.
Lastly there is a piece of assembly: 5 times invocation of the msr cpsr_c assembly instruction, setting up the stacks for the 5 different exceptions of an ARM CPU: IRQ, ABT, UND, FIQ and SVC. msr cpsr_c can switch the CPU into different contexts and set up the hardware-specific sp for each of these contexts. The CPU stores these copies of the sp internally.
The first assembly instruction loads the address of the variable stk, then this is offsetted for the struct members irq[0], abt[0], und[0], and fiq[0]. The struct stack where this is all stored was located in the beginning of the cpu_init() with these two codelines:
unsigned int cpu = smp_processor_id();
struct stack *stk = &stacks[cpu];
stacks is just a file-local struct in a cacheline-aligned variable:
struct stack {
u32 irq[3];
u32 abt[3];
u32 und[3];
u32 fiq[3];
} ____cacheline_aligned;
static struct stack stacks[NR_CPUS];
In the ARM32 case cacheline-aligned means this structure will start on an even 32, 64 or 128-byte boundary. Most commonly a 32-byte boundary, as this is the most common cacheline size on ARM32.
So we define as many exception callstacks as there are CPUs in the system. Interrupts and other exceptions thus have 3 words of callstack. We will later in this article descript how we set up the exception vectors for these exceptions as well.
Setting up the machine
We have managed to set up the CPU per se and we are back in the setup_arch() function. We now need to know what kind of machine we are running on to get further.
To do this we first look for a flattened device tree (DTB or device tree blob) by calling setup_machine_fdt(). If this fails we will fall back to ATAGs by calling setup_machine_tags() which was the mechanism used for boardfiles before we had device trees.
We have touched upon this machine characteristic before: the most important difference is that in device trees the hardware on the system is described using an abstract hierarchical tree structure and in ATAGs the hardware is defined in C code in a so-called boardfile, that will get called later during this initialization. There are actually to this day three ways that hardware is described in the ARM systems:
- Compile-time hardcoded: you will find that some systems such as the RISC PC or StrongARM EBSA110 (evaluation board for StrongARM 110) will have special sections even in head.S using
#ifdef CONFIG_ARCH_RPC and similar constructs to kick in machine-specific code at certain stages of the boot. This was how the ARM32 kernel was started in 1994-1998 and at the time very few machines were supported. This was the state of the ARM32 Linux kernel as it was merged into the mainline in kernel v2.1.80.
- Machine number + ATAGs-based: as the number of ARM machines grew quickly following the successful Linux port, the kernel had to stop relying on compile-time constants and needed a way for the kernel to identify which machine it was running on at boot time rather than at compile time. For this reason ATAGs were introduced in 2002. The ATAGs are also called the kernel tagged list and they are a simple linked list in memory passed to the kernel at boot, and most importantly provides information about the machine type, physical memory location and size. The machine type is what we need to call into the right boardfile and perform the rest of the device population at runtime. The ATAGs are however not used to identify the very machine itself. To identify the machine the boot loader also passes a 32bit number in
r1, then a long list of numbers identifying each machine, called mach-types, is compiled into the kernel to match this number.
- Device Tree-based: the Android heist in 2007 and onward started to generate a constant influx of new machine types to the ARM kernel, and the board files were growing wild. In 2010 Grant Likely proposed that ARM follow PowerPC and switch to using device trees to describe the hardware, rather than ATAGs and boardfiles. In 2011 following an outburst from Torvalds in march, the situation was becoming unmaintainable and the ARM community started to accelerate to consolidate the kernel around using device trees rather than boardfiles to cut down on kernel churn. Since then, the majority of ARM32 boards use the device tree to describe the hardware. This pattern has been followed by new architectures: Device Tree is established as the current most viable system description model for new machines.
All of the approaches use the kernel device and driver model to eventually represent the devices in the kernel – however during the very early stages of boot the most basic building blocks of the kernel may need to shortcut this to some extent, as we will see.
Whether we use ATAGs or a DTB, a pointer to this data structure is passed in register r2 when booting the kernel and stored away in the global variable __atags_pointer. The name is a bit confusing since it can also point to a DTB. When using ATAGs a second global variable named __machine_arch_type is also used, and this contains register r1 as passed from the boot loader. (This value is unused when booting from a device tree.)
Using the ATAGs or the DTB, a machine descriptor is located. This is found either from the numerical value identifying the machine in __machine_arch_type or by parsing the DTB to inspect the .compatible value of the machine, at the very top node of the device tree.
While ARM32 device tree systems are mainly relying on the device tree to boot, they also still need to match against a machine descriptor in some file under arch/arm/mach-*/*.c, defined with the macro DT_MACHINE_START. A simple grep DT_MACHINE_START gives you an idea of how many basic ARM32 machine types that boot from the device tree. The ARM64 (Aarch64) kernel, by contrast, has been engineered from start not to require any such custom machine descriptors and that is why it is not found in that part of the kernel. On ARM64, the device trees is the sole machine description.
If you inspect the arch/arm/kernel/devtree.c file you will see that a default device tree machine named Generic DT based system is defined if we are booting a multiplatform image. If no machine in any subdirectory matches the compatible-string of the device tree, this one will kick in. This way it is possible to rely on defaults and boot an ARM32 system with nothing but a device tree, provided you do not need any fix-ups of any kind. Currently quite a lot of ARM32 machines have some quirks though. ARM64 again, have no quirks on the machine level: if quirks are needed for some hardware, these will normally go into the drivers for the machine, and gets detected on a more fine-granular basis using the compatible-string or data found in hardware registers. Sometimes the ARM64 machines use firmware calls.
In either case the physical address pointing to the data structure for ATAGs or DTB is converted to a virtual address using __phys_to_virt() which involves a bit of trickery as we have described in an earlier article about phys_to_virt patching.
Memory Blocks – Part 1
One of the more important effects of calling either setup_machine_fdt() or setup_machine_tags() depending on machine, is the population of a list of memory blocks, memblocks or regions, which is the basic boot-time unit of physical RAM in Linux. Memblocks is the early memory abstraction in Linux and should be contiguous (follow each other strictly in memory). The implementation as used by all Linux architectures can be found in mm/memblock.c.
Either parser (device tree or ATAGs) identifies blocks of physical memory that are added to a list of memory blocks using the function arm_add_memory(). The memory blocks (regions) are identified with start and size, for example a common case is 128MB of memory starting at 0x00000000 so that will be a memory block with start = 0x00000000 and size = 0x08000000 (128 MB).
The memory blocks are actually stored in struct memblock_region which have members .base and .size for these two numbers, plus a flag field.
The ATAG parser calls arm_add_memory() which will adjust the memory block a bit if it has odd size: the memory block must start at a page boundary, be inside a 32bit physical address space (if we are not using LPAE), and it must certainly be on or above PHYS_OFFSET.
When arm_add_memory() has aligned a memory block it will call a facility in the generic memory manager of the Linux kernel with memblock_add() which will in effect store the list of memory blocks in a kernel-wide global list variable with the helpful name memory.
Why must the memory blocks be on or above (i.e. at higher address) than PHYS_OFFSET?
This is because of what has been said earlier about boot: we must load the kernel into the first block of physical memory. However the effect of this check is usually nothing. PHYS_OFFSET is, on all modern platforms, set to 0x00000000. This is because they all use physical-to-virtual patching at runtime. So on modern systems, as far as memory blocks are concerned: anything goes as long as they fit inside a 32-bit physical memory address space.
Consequently, the device tree parser we enter through setup_machine_fdt() does not care about adjusting the memory blocks to PHYS_OFFSET: it will end up in early_init_dt_scan_memory() in drivers/of/fdt.c which calls early_init_dt_add_memory_arch() which just aligns the memory block to a page and add it to the list with memblock_add(). This device tree parsing code is shared among other Linux architectures such as ARC or ARM64 (Aarch64).
When we later want to inspect these memory blocks, we just use the iterator for_each_mem_range() to loop over them. The vast majority of ARM32 systems have exactly one memory block/region, starting at 0x00000000, but oddities exist and these are handled by this code. An example I will use later involves two memory blocks 0x00000000-0x20000000 and 0x20000000-0x40000000 comprising 2 x 512 MB of memory resulting in 1 GB of physical core memory.
Initial Virtual Memory init_mm
After some assigning of variables for the machine, and setting up the reboot mode from the machine descriptor we then hit this:
init_mm.start_code = (unsigned long) _text;
init_mm.end_code = (unsigned long) _etext;
init_mm.end_data = (unsigned long) _edata;
init_mm.brk = (unsigned long) _end;
init_mm is the initial memory management context and this is a compile-time prepared global variable in mm/init-mm.c.
As you can see we assign some variables to the (virtual) addresses of the kernel .text and .data segments. Actually this also covers the BSS section, that we have initialized to zero earlier in the boot process, as _end follows after the BSS section. The initial memory management context needs to know these things to properly set up the virtual memory. This will not be used until much later, after we have exited setup_arch() and get to the call to the function init_mm(). (Remember that we are currently still running in a rough 1MB-chunk-section mapping.)
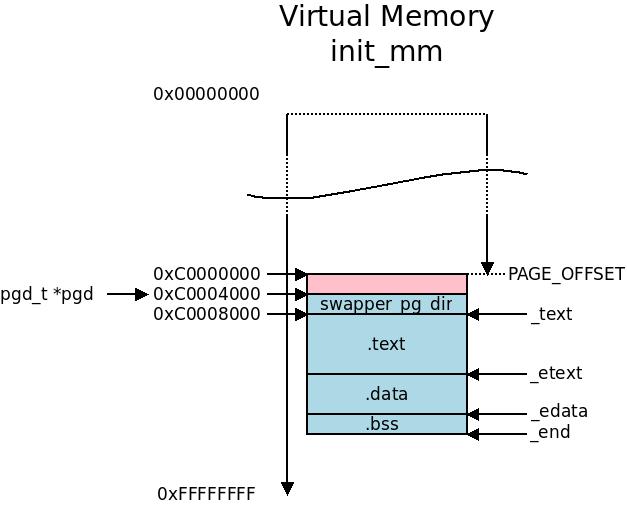 Here we can see the area where the kernel memory starts at
Here we can see the area where the kernel memory starts at PAGE_OFFSET and how we align in the different sections into init_mm. The swapper_pg_dir is actually the page global directory of the init_mm structure as we will see later.
The Early Fixmap and early_mm_init()
Next we initialize the early fixmap. The fixmap is a virtual memory area from 0xFFC00000-0xFFF00000 where some fixed physical-to-virtual mappings can be specified. They are used for remapping some crucial parts of the memory as well as some I/O memory before the proper paging is up, so we poke around in the page table in a simplified manner and we can do a few necessary I/O operations in the virtual memory even before the proper set-up of the virtual memory.
There are four types of fixmaps on ARM32, all found in arch/arm/include/asm/fixmap.h where enum fixed_addresses define slots to be used for different early I/O maps:
FIX_EARLYCON: this is a slot used by the early console TTY driver. Some serial line drivers have a special early console callback that can be used to get an early console before the actual serial driver framework has started. This is supported on ARM32 but it has a very limited value, because on ARM32 we have CONFIG_DEBUG_LL which provides a hardcoded serial port at compile time, which makes it possible to get debug output on the serial port even before we are running in virtual memory, as we have seen earlier. CONFIG_DEBUG_LL cannot be used on a multiplatform image and has the upside of using the standard serial port driver callbacks, the serial port defines an EARLYCON_DECLARE() callback and assigns functions to ->con->write/read to get both read and write support on the early console.FIX_KMAP: As can be seen from the code, this is KM_TYPE_NR * NR_CPUS. KM_TYPE_NR is tied down to 16 for ARM32, so this will be 16 maps for each CPU. This area is used for high memory “highmem”. Highmem on ARM32 is a whole story on its own and we will detail it later, but it relates to the way that the kernel uses a linear map of memory (by patching physical to virtual memory mapping as we have seen), but for now it will suffice to say that this is where memory that cannot be accessed by using the linear map (a simple addition or subtraction to get between physical and virtual memory) is temporarily mapped in so that the kernel can make use of it. The typical use case will be page cache.FIX_TEXT_POKE[0|1]: These two slots are used by debug code to make some kernel text segments writable, such as when inserting breakpoints into the code. The fixmap will open a “window” over the code that it needs to patch, modify the code and close the window again.FIX_BTMAPS: This is parameterization for 32 * 7 slots of mappings used by early ioremap, see below.
Those early fixmaps are set up during boot as we call:
pmd_t *pmd;
pmd = fixmap_pmd(FIXADDR_TOP);
pmd_populate_kernel(&init_mm, pmd, bm_pte);
The abbreviations used here include kernel page table idiosyncracies so it might be a good time to read my article on how the ARM32 page tables work.
This will create an entry in the page middle directory (PMD) and sufficient page table entries (PTE) referring to the memory at FIXADDR_TOP, and populate it with the finer granular page table entries found in bm_pte. The page table entries in bm_pte uses PAGE_SIZE granularity so usually this is a number of 0x1000 sized windows from virtual to physical memory. FIXADDR_TOP points to the last page in the FIXADDR address space, so this will be at 0xFFF00000 - PAGE_SIZE so typically at 0xFFEFF000..0xFFEFFFF. The &init_mm parameter is actually ignored, we just set up this PMD using the PTEs in bm_pte. Finally the memory storing the PMD itself is flushed in the translation lookaside buffer so we know the MMU has the right picture of the world.
Did we initialize the init_mm->pgd member now again? Nope. init_mm is a global variable defined in <linux/mm_types.h> as extern struct mm_struct init_mm, and the struct mm_struct itself is also defined in this header. To find init_mm you need to look into the core kernel virtual memory management code in mm/init-mm.c and there it is:
struct mm_struct init_mm = {
.mm_rb = RB_ROOT,
.pgd = swapper_pg_dir,
(...)
};
So this is assigned at compile time to point to swapper_pg_dir, which we know already to contain our crude 1MB section mappings. We cross our fingers, hope that our fixmap will not collide with any of the existing 1MB section mappings, and just push a more complex, proper “PMD” entry into this PGD area called swapper_pg_dir. It will work fine.
So we still have our initial 1MB-sized section mappings, and to this we have added an entry to this new “PMD”, which in turn point to the page table entry bm_pte which stores our fixmaps.
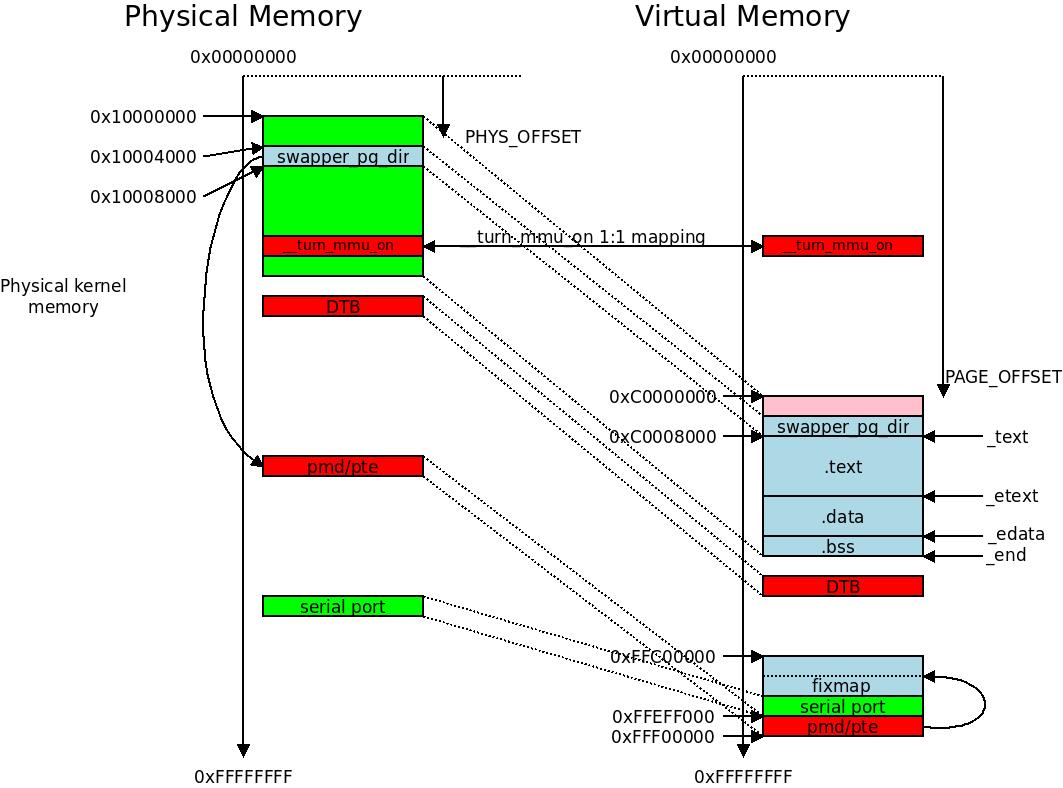 This illustrates the world of the
This illustrates the world of the init_mm memory management context. It is getting crowded in this picture. You can see the fixmap entries piling up around 0xFFF00000 and the serial port mapped in as one of the fixmaps.
Code will have to assign the physical base address (aligned to a page boundary) to use for each slot in the fixmap, and the kernel will assign and map a suitable virtual address for the physical address, for example the early console does this:
set_fixmap(FIX_EARLYCON, <physical address>);
This just loops back to __set_fixmap() in arch/arm/mm/mmu.c that looks up which virtual address has been assigned for this index (in this case the index is FIX_EARLYCON) by using __fix_to_virt() from the generic part of the fixmap in include/asm-generic/fixmap.h. There are two functions for cross referencing virtual to physical memory and vice versa that look like this:
#define __fix_to_virt(x) (FIXADDR_TOP - ((x) << PAGE_SHIFT))
#define __virt_to_fix(x) ((FIXADDR_TOP - ((x)&PAGE_MASK)) >> PAGE_SHIFT)
As you can see, the fixmap remappings are done one page at the time (so each remapping is one single page), backwards from FIXADDR_TOP (on ARM32 0xFFEFF000) so the first index for FIX_EARLYCON will be a page at 0xFFEFE000, the second index at 0xFFEFD000 etc.
It then looks up the PTE for this virtual address using pte_offset_fixmap():
pte_t *pte = pte_offset_fixmap(pmd_off_k(vaddr), vaddr);
Which at this point is a pointer to pte_offset_early_fixmap():
static pte_t * __init pte_offset_early_fixmap(pmd_t *dir, unsigned long addr)
{
return &bm_pte[pte_index(addr)];
}
So we simply get a pointer to the PTE inside the bm_pte page table, which makes sense since this is the early fixmap page table where these page table entries physically reside.
Then set_fixmap() will modify the page table entry in the already registered and populated bm_pte page table by calling set_pte_at() which call set_pte_ext() which will eventually call down into per-CPU assembly symbol set_pte_ext in arch/arm/mm/proc-*.S This will conjure the right value for the PTE and write that back to the page table in the right slot, so that the virtual-to-physical mapping actually happens.
After this we call local_flush_tlb_kernel_range() just to make sure we don’t have this entry stored in the translation lookaside buffer for the CPU. We can now access the just remapped physical memory for the early console in the virtual address space. It better not be more than one page, but it’s cool: there is no memory mapped serial port that uses more than one page of memory. It will “just work”.
The early fixmaps will eventually be converted to proper (non-fixed) mappings once we call early_fixmap_shutdown() inside paging_init() which will be described later. Curiously only I/O memory is supported here. We better not use any fixmaps before early_fixmap_shutdown() that are not I/O memory and expect them to still be around after this point. This should be safe: the patching in the poke windows and the highmem business should not happen until later anyways.
As I noted the FIX_BTMAPS inside the early fixmaps are used for I/O memory. So this comes next, as well call early_ioremap_init(). As ARM32 is using the generic early ioremap code this just calls early_ioremap_setup() in mm/early_ioremap.c. This makes it possible to use early calls to ioremap(). As noted we have defined for NR_FIX_BTMAPS which we use to parameterize the generic early ioremap code. We can early ioremap 32 different memory areas.
For drivers it will transparently provide a back-end for ioremap() so that a piece of I/O memory can be remapped to a virtual address already at this point, and stay there, usually for the uptime of the system. A driver requesting an ioremap at this point will get a virtual-to-physical mapping in the assigned virtual memory area somewhere in the range 0xFFC00000-0xFFF00000 and it stays there.
Which device drivers will use these early ioremaps to get to the memory-mapped I/O? The early console is using it’s own fixmap so not that one. Well. actually not much as it looks. But it’s available.
Later, at runtime, the fixmaps will find another good use: they are used to map in highmem: memory that the kernel cannot handle due to being outside of the linear kernel map. Such areas will be mapped in here one piece at a time. This is causing complexities in the highmem handling, and is why we are investigating an end to highmem. If you do not know what highmem means in this context – do not worry! – it will be explained in more detail below.
Early Parameters
We have just set up some early mappings for the early console, so when we next call parse_early_param() in init/main.c to read a few command line parameters that just cannot wait. As the documentation in <linux/init.h> says: “only for really core code”.
Before we set up the early fixmap we actually copied the boot_command_line. This was already present since the call to setup_machine_fdt() or setup_machine_tags(). During the parsing of ATAGs or the DTB, boot_command_line is assigned from either source. So a kernel command line can be passed in from each of these two facilities. Parameters to the kernel can naturally be passed in on this command line.
The normal way to edit and pass these command line arguments is by using a facility in U-Boot, UEFI or GRUB to set them up in the boot loader before booting the kernel. U-Boot for example will either pass them in a special ATAG (old way) or by modifying the chosen node of the device tree in memory before passing a pointer to the device tree to the kernel in r2 when booting.
The early params are defined all over the kernel compiled-in code (not in modules, naturally) using the macro early_param(). Each of these result in a struct obs_kernel_param with a callback ->setup_func() associated with them, that gets stored in a table section named .init.setup by the linker and these will be called one by one at this point.
Examples of things that get set up from early params are cache policy, extra memory segments passed with mem=..., parameters to the IRQ controllers such as noapic to turn off the x86 APIC, initrd to point out the initial RAM disk.
mem is an interesting case: this is parsed by an early_param() inside setup.c itself, and if the user passed some valid mem= options on the command line, these will be added to the list of available memory blocks that we constructed from the ATAGs or DTB.
earlycon is also parsed, which will activate the early console if this string is passed on the command line. So we just enabled the special FIX_EARLYCON early fixmap, and now the early console can use this and dump out the kernel log so far. All this happens in drivers/tty/serial/earlycon.c by utilizing the early console callbacks of the currently active serial port.
If you are using device tree, early_init_dt_scan_chosen_stdout() will be called, which will call of_setup_earlycon() on the serial driver selected in the stdout-path in the chosen section in the root of the device tree, such as this:
/ {
chosen {
stdout-path = "uart0:19200n8";
};
(...)
Or like this:
/ {
chosen {
stdout-path = &serial2;
};
(...)
serial2: uart@80007000 {
compatible = "arm,pl011", "arm,primecell";
reg = <0x80007000 0x1000>;
};
};
The device tree parsing code will follow the phandle or use the string to locate the serial port. For this reason, to get an early console on device tree systems, all you need to pass on the command line is earlycon. The rest will be figured out by the kernel by simply inspecting the device tree.
On older systems it is possible to pass the name of the driver and a memory address of a serial port, for example earlycon=pl011,0x80007000 but this is seldomly used these days. Overall the earlycon, as noted, is seldomly used on ARM32. It is because we have the even more powerful DEBUG_LL that can always hammer out something on the serial port. If you need really early debugging information, my standard goto solution is DEBUG_LL and using printascii() until the proper kernel prints have come up. If earlycon is early enough, putting the stdout-path into your device tree and specifying the earlycon parameter should do the trick on modern systems.
Early Memory Management
As we reach early_mm_init() we issue build_mem_type_table() and early_paging_init() in sequence. This is done so that we can map the Linux memory the way it is supposed to be mapped using all features of the MMU to the greatest extent possible. In reality, this involves setting up the “extra bits” in the level-2/3 page descriptors corresponding to the page table pointer entries (PTE:s) so the MMU knows what to do.
build_mem_type_table() will fill in the mem_types[] array of memory types with the appropriate protection and access settings for the CPU we are running on. mem_types[] is an array of some 16 different memory types that can be found inside arch/arm/mm/mmu.c and list all the memory types that may exist in an ARM32 system, for example MT_DEVICE for memory-mapped I/O or MT_MEMORY_RWX for RAM that can be read, written and executed. The memory type will determine how the page descriptors for a certain type of memory gets set up. At the end of building this array, the kernel will print out some basic information about the current main memory policy, such as:
Memory policy: ECC enabled, Data cache, writeback
This tells us that was turned on by passing ecc=on on the command line, with the writeback data cache policy, which is the default. The message is a bit misleading since it actually just talks about a few select aspects of the memory policy regarding the use of ECC and the data cache. There are many other aspects to the cache policy that can be seen by inspecting the mmu.c file. It is not normal to pass in ecc=on, so this is just an example.
early_paging_init() then, is a function that calls ->pv_fixup() on the machine, and this is currently only used on the Texas Instruments Keystone 2 and really just does something useful when the symbol CONFIG_ARM_PV_FIXUP is defined. What happens then is that an address space bigger than 4GB is enabled using LPAE. This is especially complicated since on this machine even the physical addresses changes as part of the process and PHYS_OFFSET is moved upwards. The majority of ARM32 machines never do this.
We do some minor initialization calls that are required before kicking in the proper paging such as setting up the DMA zone, early calls to Xen (virtualization) and EFI. Then we get to the core of the proper Linux paging.
Paging Initialization: Lowmem and Highmem
We now reach the point where the kernel will initialize the virtual memory handling proper, using all the bells and whistles of the MMU.
The first thing we do is to identify the bounds of lowmem. ARM32 differentiates between lowmem and highmem like this:
- Lowmem is the physical memory used by the kernel linear mapping. This is typically the virtual memory between
0xC0000000-0xF0000000, 768 MB. With an alternative virtual memory split, such as VMSPLIT_1G giving userspace 0x40000000 and kernelspace 0xC0000000 lowmem would instead be 0x40000000-0xD0000000, 2.8 GB. But this is uncommon: almost everyone and their dog uses the default VMSPLIT with 768 MB lowmem.
- Highmem is any memory at higher physical addresses, that we cannot fit inside the lowmem linear physical-to-virtual map.
You might remember that this linear map between physical and virtual memory was important for ARM32. It is achieved by physical-to-virtual runtime patching as explained in a previous article, with the goal of being as efficient as possible.
As you can see, on ARM32 both lowmem and highmem have a very peculiar definition and those are just conventions, they have very little to do with any hardware limitations of the architecture or any other random definitions of “lowmem” and “highmem” that are out there.
A system can certainly have less than 768 MB (0x30000000) physical memory as well: then all is fine. The kernel can map in and access any memory and everyone is happy. For 14 years all ARM32 systems were like this, and “highmem” did not even exist as a concept. Highmem was added to ARM32 by Nicolas Pitre in september 2008. The use case was a Marvell DB-78x00-BP development board that happened to have 2 GB of RAM. Highmem requires fixmap support so that was added at the same time.
The kernel currently relies on being able to map all of the core memory – the memory used by the kernel itself, and all the userspace memory on the machine – into its own virtual memory space. This means that the kernel cannot readily handle a physical memory bigger than 768 MB, with the standard VMSPLIT at 0xC0000000. To handle any memory outside of these 768 MB, the FIX_KMAP windows in the fixmaps we discussed earlier are used.
Let’s inspect how this 768 MB limitation comes about.
To calculate the end of lowmem we call adjust_lowmem_bounds(), but first notice this compiled-in constant a little bit above that function:
static void * __initdata vmalloc_min =
(void *)(VMALLOC_END - (240 << 20) - VMALLOC_OFFSET);
vmalloc is shorthand for virtual memory allocation area, and indicates the memory area where the kernel allocates memory windows. It has nothing to do with the physical memory of the kernel at this point: it is an area of virtual addresses that the kernel can use to place mappings of RAM or memory-mapped I/O. It will be used by SLAB and other kernel memory allocators as well as by ioremap(), it is a number of addresses in the kernel’s virtual memory that it will be using to access random stuff in physical memory. As we noted, we had to use early fixmaps up to this point, and the reason is exactly this: there is no vmalloc area to map stuff into yet.
The variables used for this pointer can be found in arch/arm/include/asm/pgtable.h:
#define VMALLOC_OFFSET (8*1024*1024)
#define VMALLOC_START (((unsigned long)high_memory + VMALLOC_OFFSET) & ~(VMALLOC_OFFSET-1))
#define VMALLOC_END 0xff800000UL
Never mind the high_memory variable in VMALLOC_START: it has not been assigned yet. We have no idea about where the virtual memory allocation will start at this point.
VMALLOC_END is hardcoded to 0xFF800000, (240 << 20) is an interesting way of writing 0x0F000000 and VMALLOC_OFFSET is 0x00800000. So vmalloc_min will be a pointer to the virtual address 0xF0000000. This lower bound has been chosen for historical reasons, which can be studied in the commit. Above this, all the way to 0xFF800000 we will find our vmalloc area.
From this we calculate the vmalloc_limit as the physical address corresponding to vmalloc_min, i.e. what address in the physical memory the virtual address 0xF0000000 corresponds to in the linear map of physical-to-virtual memory. If our kernel was loaded/decompressed at 0x10008000 for example, that usually corresponds to 0xC0008000 and so the offset is 0xB0000000 and the corresponding physical address for 0xF0000000 would be 0xF0000000 - 0xB0000000 = 0x40000000. So this is our calculated vmalloc_limit.
We arrive at the following conclusion: since the kernel starts at 0x10000000 (in this example) and the linear map of the kernel stretches from 0x10000000-0x40000000 (in virtual address space 0xC0000000-0xF0000000) That would be the equivalent of 0x30000000 bytes of memory, i.e. 768MB. This holds in general: the linear map of the kernel memory is 768 MB. The kernel and all memory it directly references must fit in this area.
In adjust_lowmem_bounds() we first loop over all memblocks to skip over those that are not “PMD-aligned” which means they do not start at a physical address evenly divisible by 0x00200000 (2 MB) on ARM systems. These are marked nomap in the memblock mechanism, so they will not be considered for kernel mappings.
The patch-phys-to-virt mechanism and the way we map page tables over the kernel relies on the kernel being at a PMD boundary so we will not be able to use memory blocks that do not start at a PMD-aligned memory address. If the memory block is such an off thing, such as when a machine has some small memories at random locations for things like graphics or other buffers, these will not be considered as a candidate for the core of the system. You can think about this as a heuristic that says: “small memories are probably not supposed to be used as main RAM memory”.
The next loop is more interesting. Here we again loop over the memblocks, but skip over those we just marked as unfit for the core memory. For those that remain we check if they start below vmalloc_limit (in our example at 0x40000000). As the memory we are executing inside certainly must start below vmalloc_limit we have a core memory candidate and inspect it further: if the block ends above the current lowmem_limit we bump lowmem_limit to the end of the block, unless it would go past vmalloc_limit, in that case we will truncate it at vmalloc_limit. This will in effect fit the core memory candidate over the 768 MB available for lowmem, and make sure that lowmem_limit is at the end of the highest memblock we can use for the kernel alternatively at the hard vmalloc_limit if that is lower than the end of the memblock. vmalloc_limit in turn is just calculated by subtracting vmalloc_reserve from VMALLOC_END, and that is parsed from a command line argument, so if someone passed in a minimum size of vmalloc reservation space, that will be respected.
In most cases arm_vmalloc_limit will be at the end of the highest located memblock. Very often there is just one big enough memblock on a given system.
The loop is necessary: there could be two blocks of physical memory adjacent to each other. Say one memblock at 0x00000000-0x20000000 and another memblock at 0x20000000-0x40000000 giving 2 x 512 MB = 1 GB of core memory. Both must be mapped to access the maximum of core memory. The latter will however be truncated by the code so that it ends at vmalloc_limit, which will be at 0x30000000 as we can only map 768 MB of memory. Oops.
The remainder of the second memblock will be called highmem if we have enabled highmem support, else we will just call memblock_remove() to delete the remainder from the system, and in this case the remaining memory will be unused so we print a warning about this: “Consider using a HIGHMEM enabled kernel.”
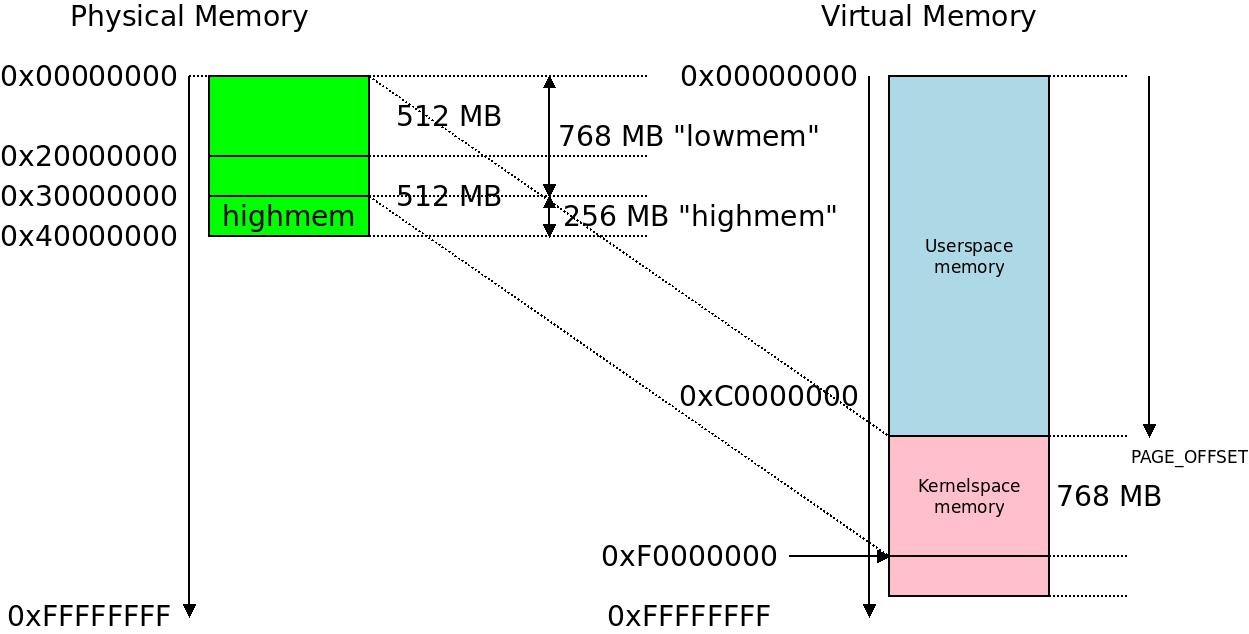 This shows how a 1 GB physical memory in two memblocks of 512 MB each starting at physical address
This shows how a 1 GB physical memory in two memblocks of 512 MB each starting at physical address 0x00000000 gets partitioned into a lowmem of 768 MB and highmem of 256 MB. The upper 256 MB cannot fit into the linear kernel memory map!
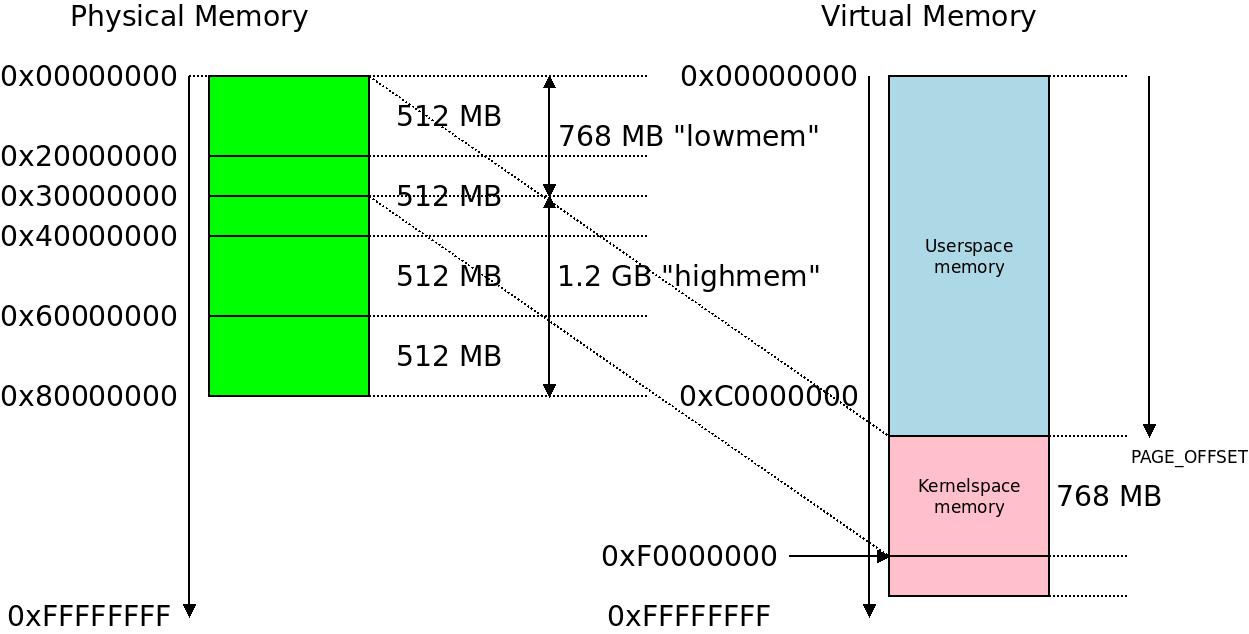 If we instead have four memblocks of 512 MB physical memory comprising a total of 2 GB, the problem becomes ever more pronounced: 1.2 GB of memory is now in highmem. This reflects the situation in the first Marvell board with 2 GB of memory that initiated the work on highmem support for ARM32.
If we instead have four memblocks of 512 MB physical memory comprising a total of 2 GB, the problem becomes ever more pronounced: 1.2 GB of memory is now in highmem. This reflects the situation in the first Marvell board with 2 GB of memory that initiated the work on highmem support for ARM32.
After exiting the function we set arm_lowmem_limit to the lowmem_limit we found. In our example with these two 512 MB banks, it will be set at physical address 0x30000000. This is aligned to the PMD granularity (0x00200000) which will again be 0x30000000, and set as a limit for memory blocks using memblock_set_current_limit(). The default limit is 0xFFFFFFFF so this will put a lower bound on where in physical memory we can make allocations with memblocks for the kernel: the kernel can now only allocate in physical memory between 0x00000000-0x30000000.
We immediately also assign high_memory to the virtual memory address right above arm_lowmem_limit, in this case 0xF0000000 of course. That means that this definition from arch/arm/include/asm/pgtable.h is now resolved:
#define VMALLOC_START (((unsigned long)high_memory + VMALLOC_OFFSET) & ~(VMALLOC_OFFSET-1))
And we find that VMALLOC_START is set to 0xF0800000. The VMALLOC area is now defined to be 0xF0800000-0xFF800000, 0x0F000000 bytes (240 MB). This looks familiar to the (240 << 20) statement in the vmalloc_min definition.
Next
This exploration will be continued in Setting Up the ARM32 Architecture, part 2 where we will take a second round around the memory blocks and set up the paging.

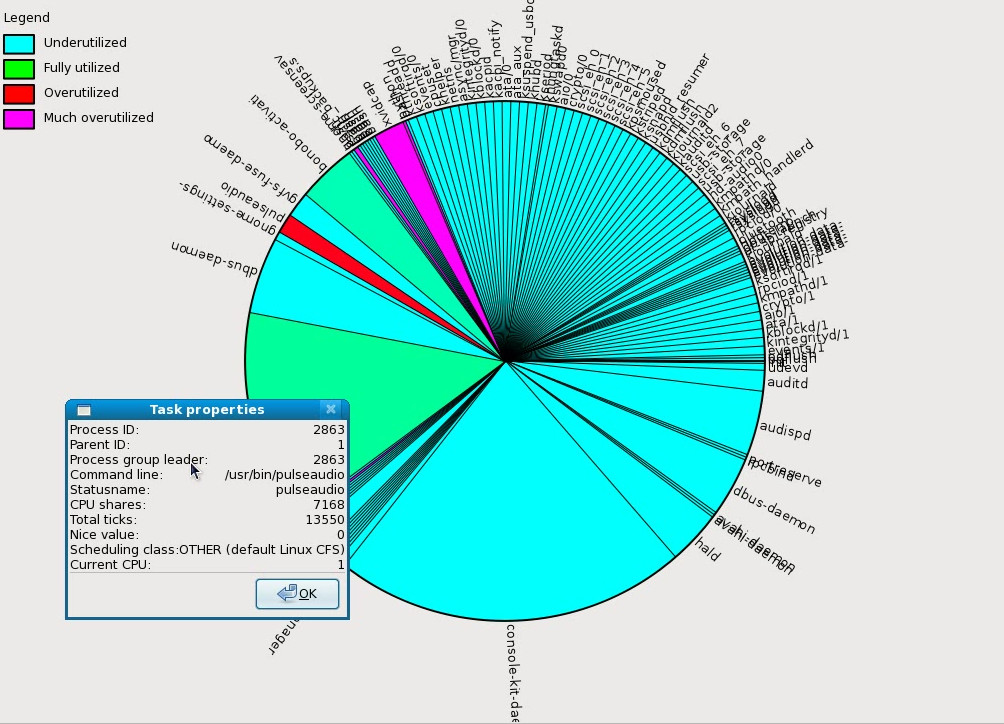 A pie chart of tasks according to priority on a certain system produced using
A pie chart of tasks according to priority on a certain system produced using 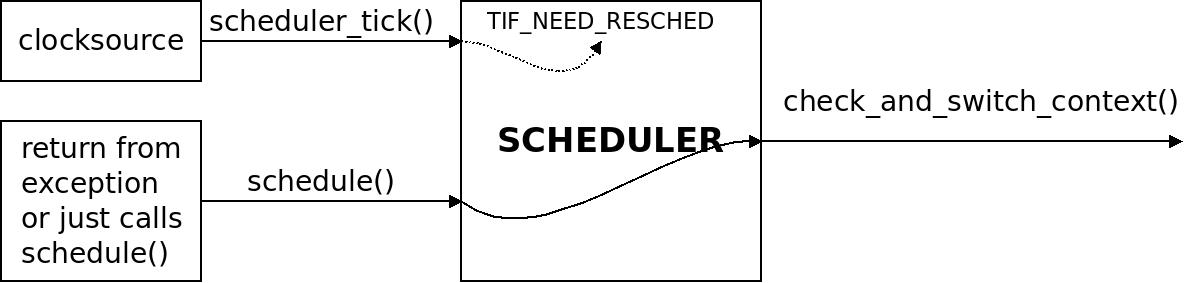 A mental model of the scheduler: scheduler_tick() sets the flag TIF_NEED_RESCHED and a later call to schedule() will actually call out to check_and_switch_context() that does the job of switching task.
A mental model of the scheduler: scheduler_tick() sets the flag TIF_NEED_RESCHED and a later call to schedule() will actually call out to check_and_switch_context() that does the job of switching task.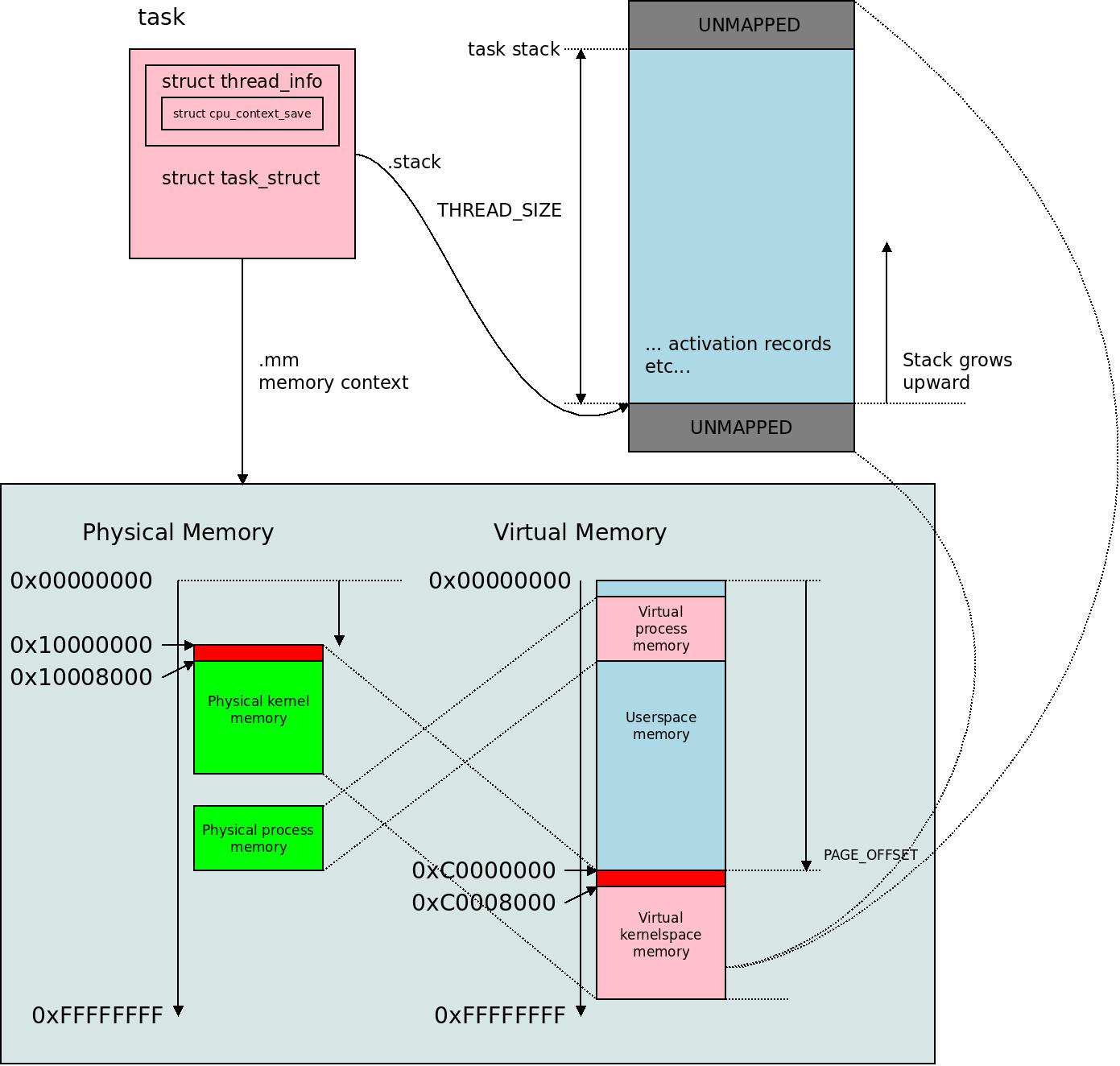 The task_struct in the Linux kernel is where the kernel keeps a nexus of all information about a certain task, i.e. a certain processing context. It contains .mm the memory context where all the virtual memory mappings live for the task. The thread_info is inside it, and inside the thread_info is a cpu_context_save. It has a task stack of size THREAD_SIZE for ARM32 which is typically twice the PAGE_SIZE, i.e. 8KB, surrounded by unmapped memory for protection. Again this memory is mapped in the memory context of the process. The split between task_struct and thread_info is such that task_struct is Linux-generic and thread_info is architecture-specific and they correspond 1-to-1.
The task_struct in the Linux kernel is where the kernel keeps a nexus of all information about a certain task, i.e. a certain processing context. It contains .mm the memory context where all the virtual memory mappings live for the task. The thread_info is inside it, and inside the thread_info is a cpu_context_save. It has a task stack of size THREAD_SIZE for ARM32 which is typically twice the PAGE_SIZE, i.e. 8KB, surrounded by unmapped memory for protection. Again this memory is mapped in the memory context of the process. The split between task_struct and thread_info is such that task_struct is Linux-generic and thread_info is architecture-specific and they correspond 1-to-1. Copies of the first specifications of ALGOL 60, belonging at one time to Carl-Erik Fröberg at Lund University.
Copies of the first specifications of ALGOL 60, belonging at one time to Carl-Erik Fröberg at Lund University.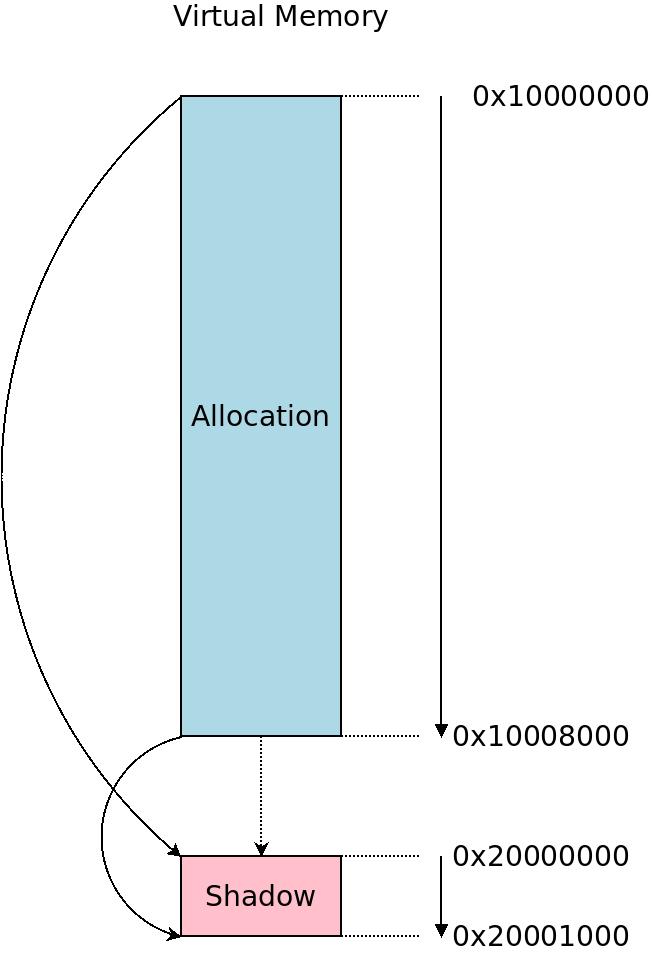 The ASan shadow memory shadows the memory you're interested in inspecting for memory safety.
The ASan shadow memory shadows the memory you're interested in inspecting for memory safety.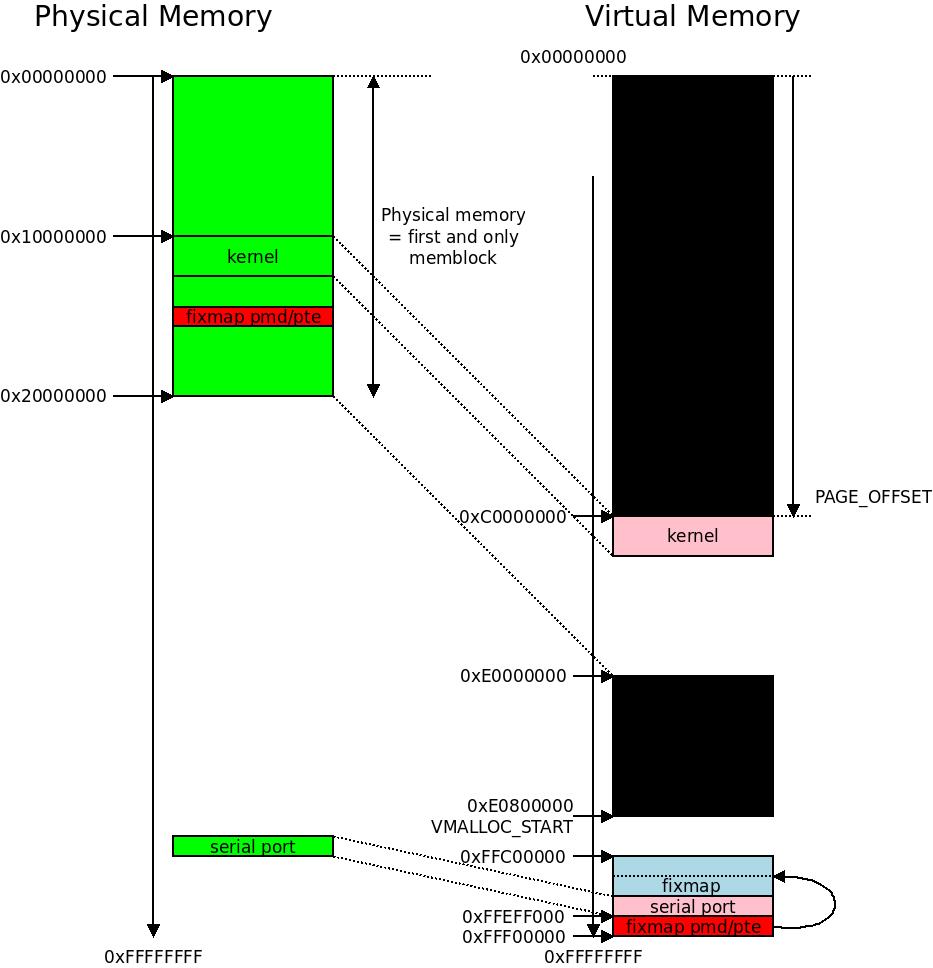 This image illustrates what happens when we initialize the PMDs (the picture is not to scale). The black blocks are the PMDs we clear, making them unavailable for any references for now. We have one block of physical memory from
This image illustrates what happens when we initialize the PMDs (the picture is not to scale). The black blocks are the PMDs we clear, making them unavailable for any references for now. We have one block of physical memory from  This illustrates how the memory above the kernel is readable/writeable, the upper part of the kernel image with the text segment is readable/writeable/executable while the lower .data and .bss part is just readable/writeable, then the rest of lowmem is also just readable writable. In this example we have 128MB (
This illustrates how the memory above the kernel is readable/writeable, the upper part of the kernel image with the text segment is readable/writeable/executable while the lower .data and .bss part is just readable/writeable, then the rest of lowmem is also just readable writable. In this example we have 128MB ( The ARM32 exception vector table is a 4KB page where the first 8 32-bit words are used as vectors. The address exception should not happen and in some manuals is described as “unused”. The program counter is simply set to this location when any of these exceptions occur. The remainder of the page is “poisoned” with the word
The ARM32 exception vector table is a 4KB page where the first 8 32-bit words are used as vectors. The address exception should not happen and in some manuals is described as “unused”. The program counter is simply set to this location when any of these exceptions occur. The remainder of the page is “poisoned” with the word 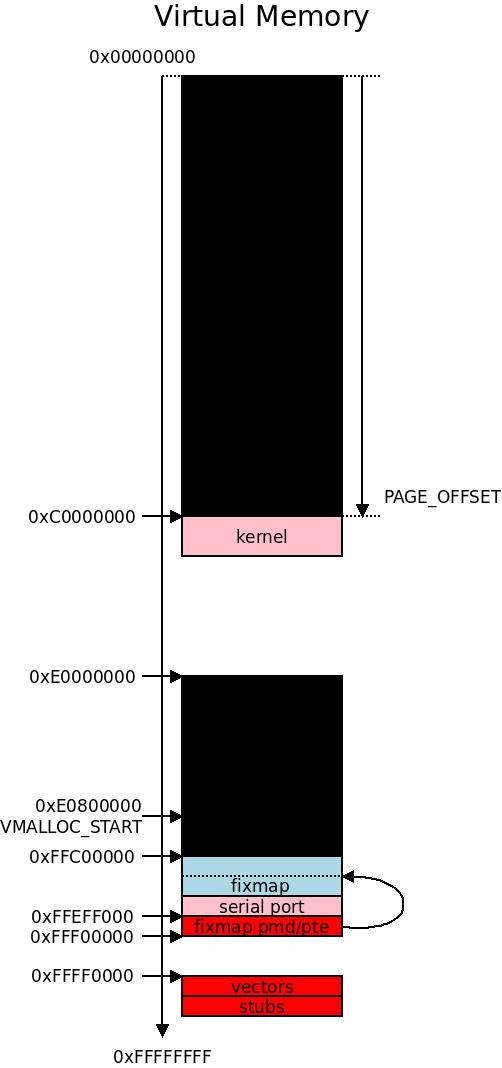 We cleared some more PMDs between
We cleared some more PMDs between 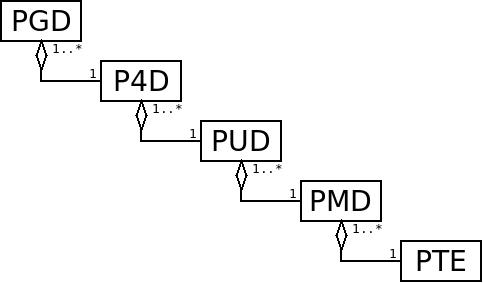 Abstract page tables in the Linux kernel proceed from the PGD (page global directory) thru the P4D (fourth level directory), PUD (page upper directory), PMD (page middle directory) and down to the actual page table entries (PTEs) that maps individual pages pages of memory from virtual to physical address space.
Abstract page tables in the Linux kernel proceed from the PGD (page global directory) thru the P4D (fourth level directory), PUD (page upper directory), PMD (page middle directory) and down to the actual page table entries (PTEs) that maps individual pages pages of memory from virtual to physical address space.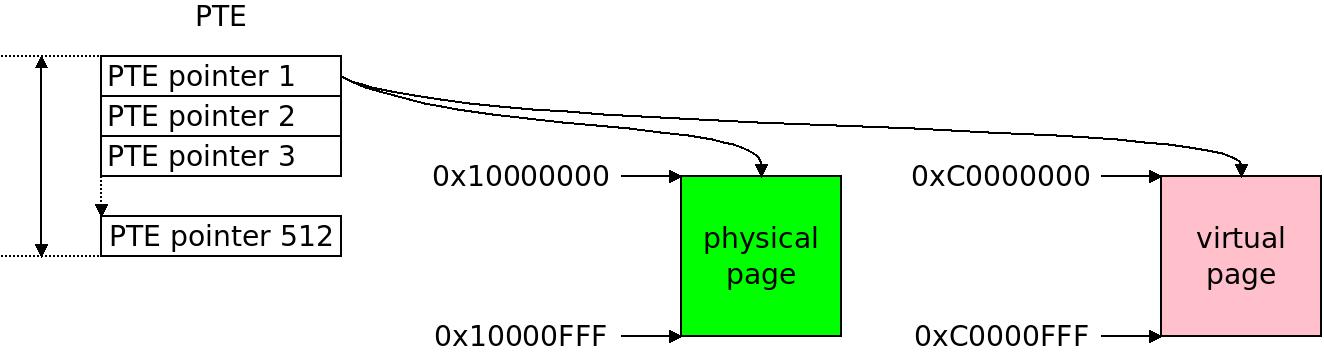 A PTE on ARM32 contains 512 pointers, i.e. translations between physical and virtual pages. From the generic kernel virtual memory management point of view it is not important how this translation actually happens in hardware, all it needs to know is that a page of size
A PTE on ARM32 contains 512 pointers, i.e. translations between physical and virtual pages. From the generic kernel virtual memory management point of view it is not important how this translation actually happens in hardware, all it needs to know is that a page of size 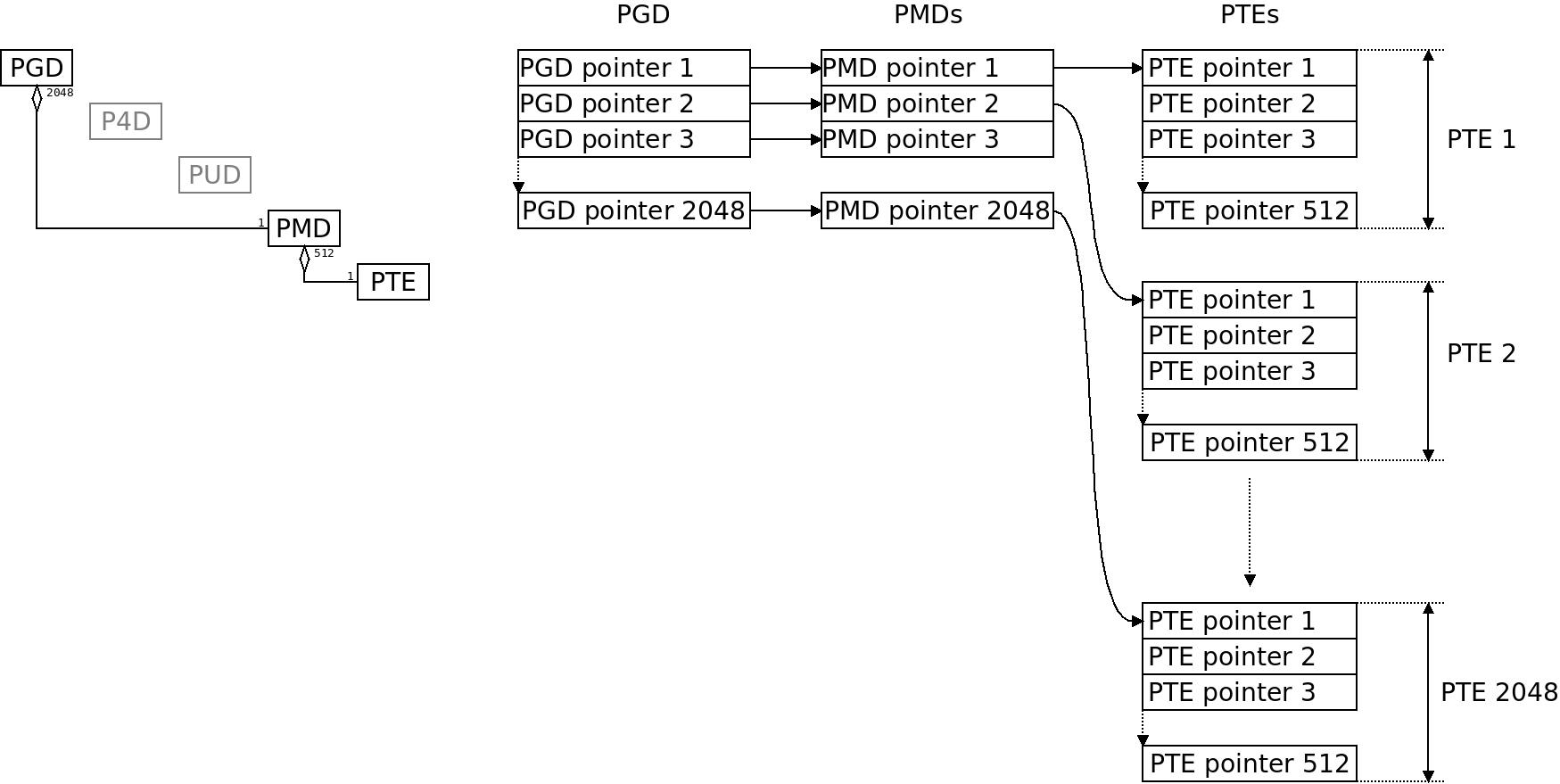 The classic ARM32 paging setup in Linux folds P4D and PUD, providing 2048 pointers per PGD, 1 pointer per PMD and 512 pointers per PTE. It uses 3 levels of the hierarchy while ARM32 hardware only has two. This is however a good fit, as we shall see. To the left the object relations, to the right an illustration of the tables.
The classic ARM32 paging setup in Linux folds P4D and PUD, providing 2048 pointers per PGD, 1 pointer per PMD and 512 pointers per PTE. It uses 3 levels of the hierarchy while ARM32 hardware only has two. This is however a good fit, as we shall see. To the left the object relations, to the right an illustration of the tables.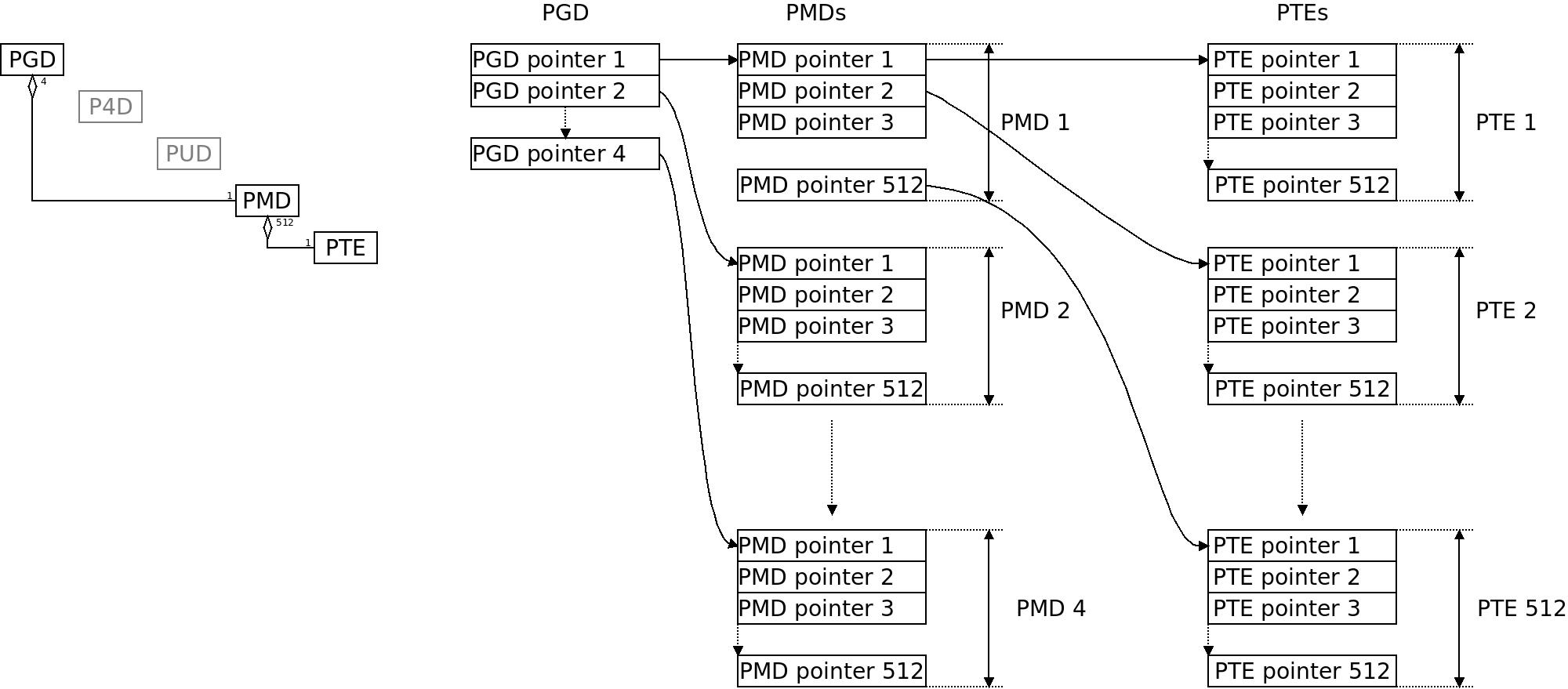 The LPAE page table also folds P4D and PUD but has something meaningful on the PMD level: 4 PGD entries covering 1 GB each covers the whole 32bit address space, then there are 512 pointers per PMD and 512 pointers per PTE. Each PTE entry translate 4KB of physical memory to virtual memory. If we would fill the PGD with all the 512 available entries it would span exactly 1 TB of memory.
The LPAE page table also folds P4D and PUD but has something meaningful on the PMD level: 4 PGD entries covering 1 GB each covers the whole 32bit address space, then there are 512 pointers per PMD and 512 pointers per PTE. Each PTE entry translate 4KB of physical memory to virtual memory. If we would fill the PGD with all the 512 available entries it would span exactly 1 TB of memory.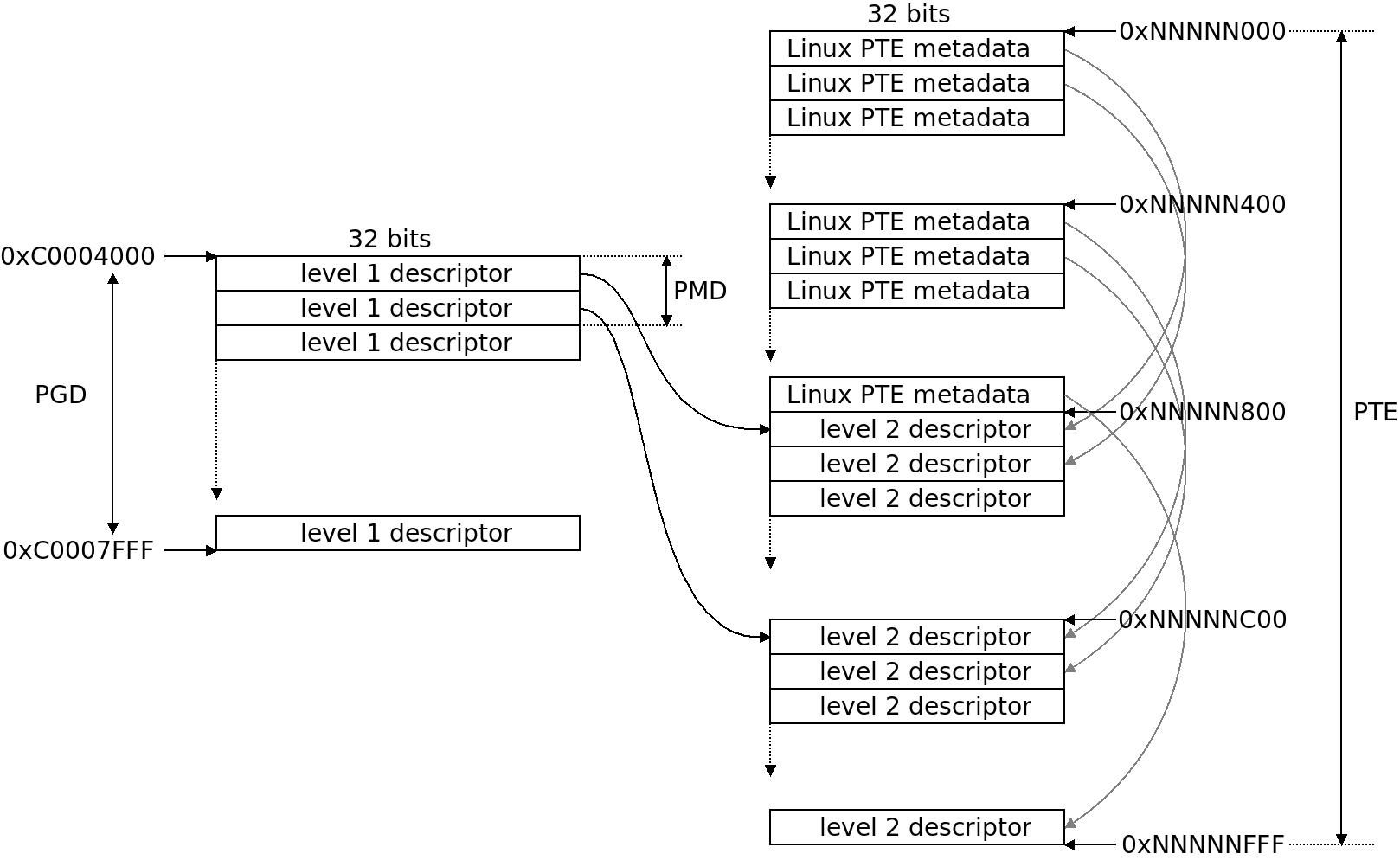 The classic ARM32 MMU page table layout uses 32bit descriptors in two levels: two level-1 descriptors in the global page table (TTB, what Linux calls PGD, page global directory) are grouped into one PMD (page middle directory). There are 4096 level-1 descriptors grouped in pairs to form a PMD so there are 2048 PMDs. Then 256 + 256 = 512 level-1 page table pointers are grouped into one PTE (page table entry) with some metadata right above it. What Linux sees is a PMD managing 2MB and a PTE managing 512 4K pages which is also 2 MB. This way a PTE fills exactly one page of memory, which simplifies things. The 4K level-2 descriptors are referred to as “coarse”.
The classic ARM32 MMU page table layout uses 32bit descriptors in two levels: two level-1 descriptors in the global page table (TTB, what Linux calls PGD, page global directory) are grouped into one PMD (page middle directory). There are 4096 level-1 descriptors grouped in pairs to form a PMD so there are 2048 PMDs. Then 256 + 256 = 512 level-1 page table pointers are grouped into one PTE (page table entry) with some metadata right above it. What Linux sees is a PMD managing 2MB and a PTE managing 512 4K pages which is also 2 MB. This way a PTE fills exactly one page of memory, which simplifies things. The 4K level-2 descriptors are referred to as “coarse”.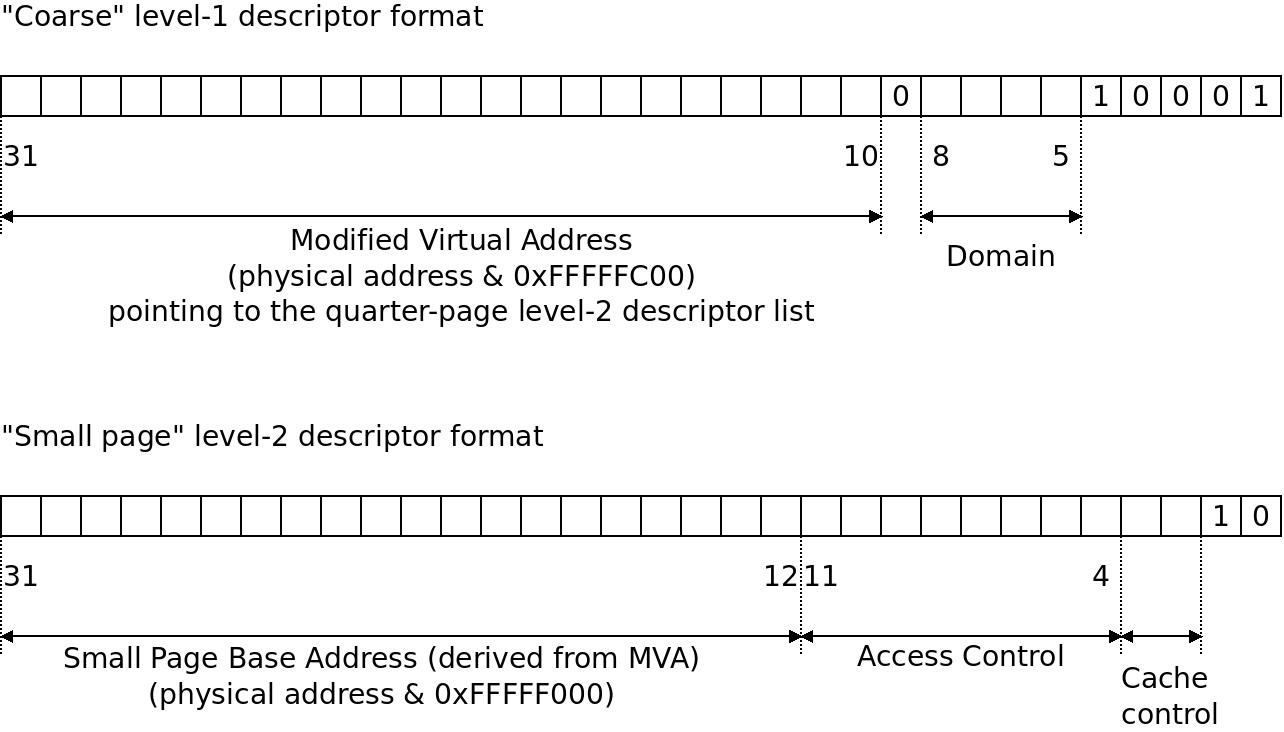 The rough format of the 32bit Level-1 and Level-2 page descriptors used in the classic ARM32 MMU, which is what most ARM32 Linux kernels use. A “coarse” level-1 descriptor points to “small page” (4KB) page descriptor. As can be seen, the memory area covered at each level is mapped by simply using the high bits of the physical address as is common in MMUs. Some domain and access control is stuffed in in the remaining bits, the bits explicitly set to 0 or 1 should be like so.
The rough format of the 32bit Level-1 and Level-2 page descriptors used in the classic ARM32 MMU, which is what most ARM32 Linux kernels use. A “coarse” level-1 descriptor points to “small page” (4KB) page descriptor. As can be seen, the memory area covered at each level is mapped by simply using the high bits of the physical address as is common in MMUs. Some domain and access control is stuffed in in the remaining bits, the bits explicitly set to 0 or 1 should be like so.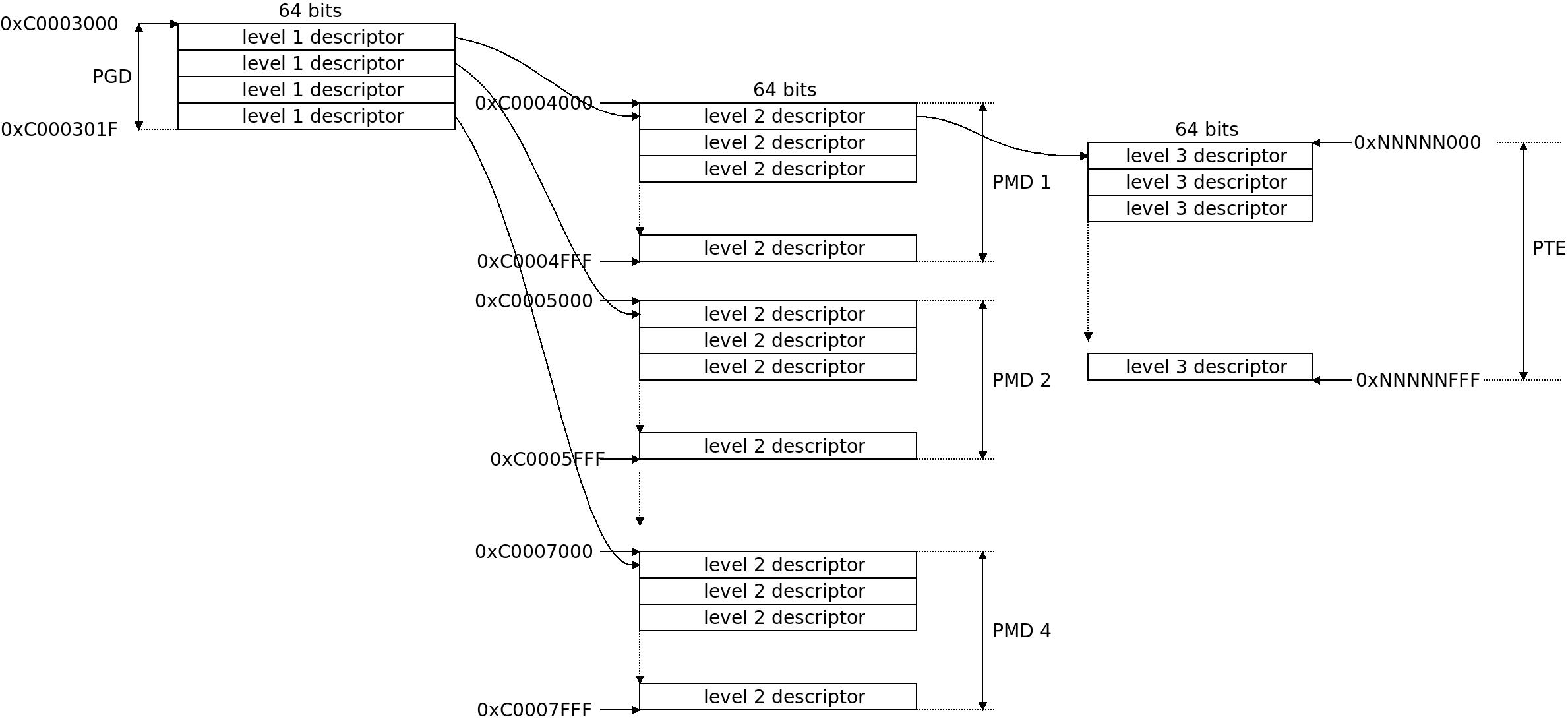 The LPAE page table layout is simpler and more intuitive than the classic MMU. 64bit pointers on each level in three levels, where one descriptor corresponds to one PGD, PMD or PTE entry, we use 4 PGD pointers consecutive at
The LPAE page table layout is simpler and more intuitive than the classic MMU. 64bit pointers on each level in three levels, where one descriptor corresponds to one PGD, PMD or PTE entry, we use 4 PGD pointers consecutive at 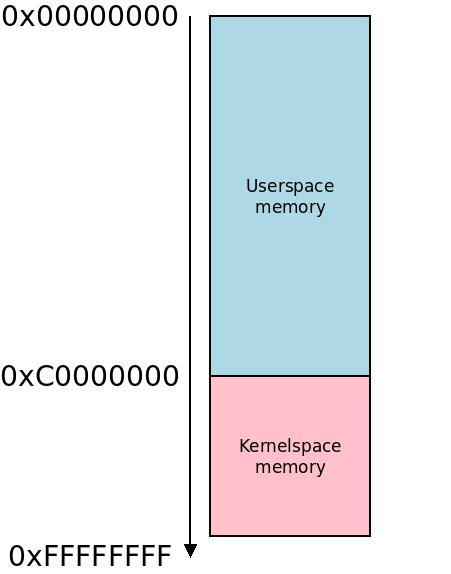 The most common virtual memory split between kernelspace and userspace memory is at
The most common virtual memory split between kernelspace and userspace memory is at 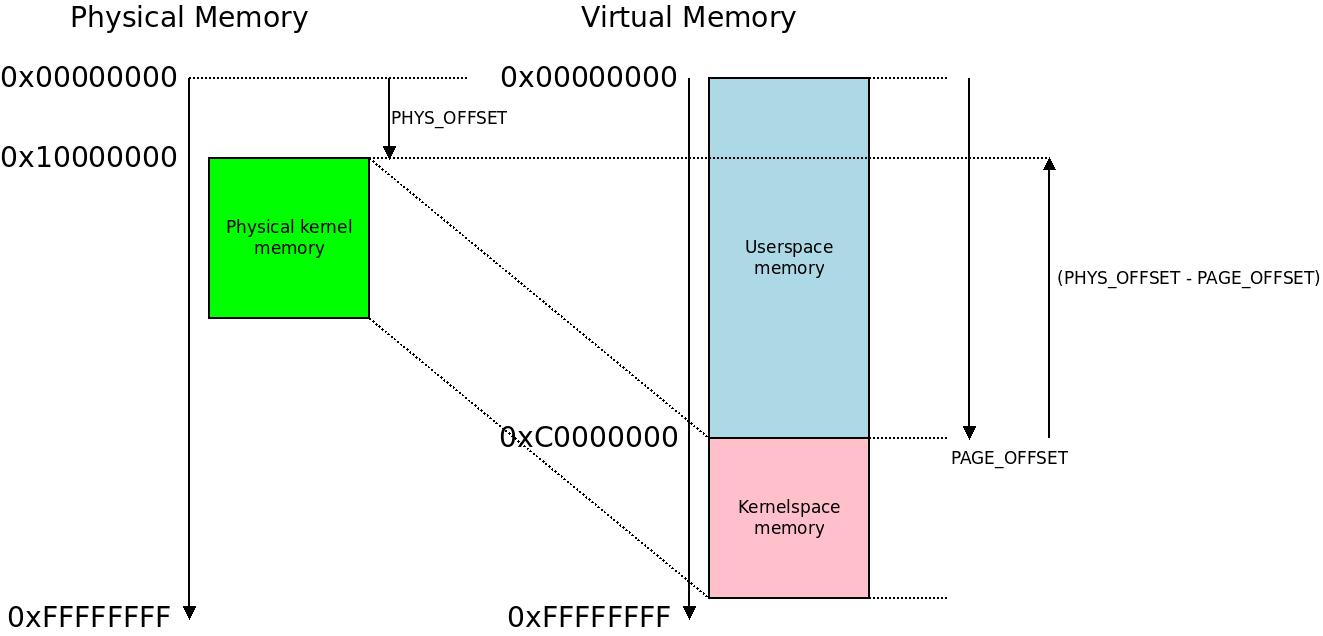 I do not know if this picture makes things easier or harder to understand. It illustrates physical to virtual memory mapping in our example.
I do not know if this picture makes things easier or harder to understand. It illustrates physical to virtual memory mapping in our example.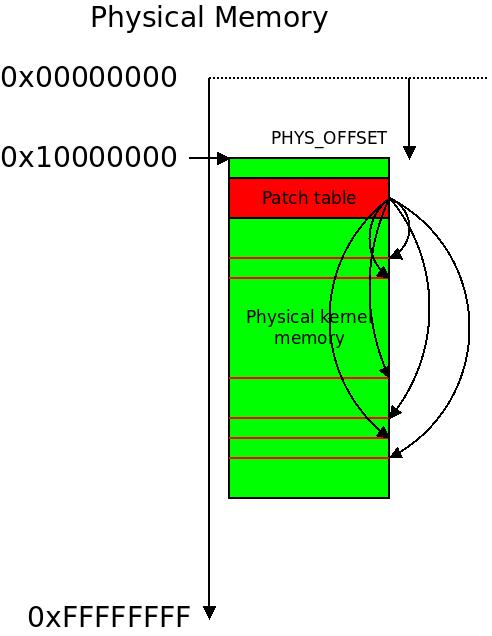 Each and every location with an assembly macro doing a translation from physical to virtual memory is patched in the early boot process.
Each and every location with an assembly macro doing a translation from physical to virtual memory is patched in the early boot process.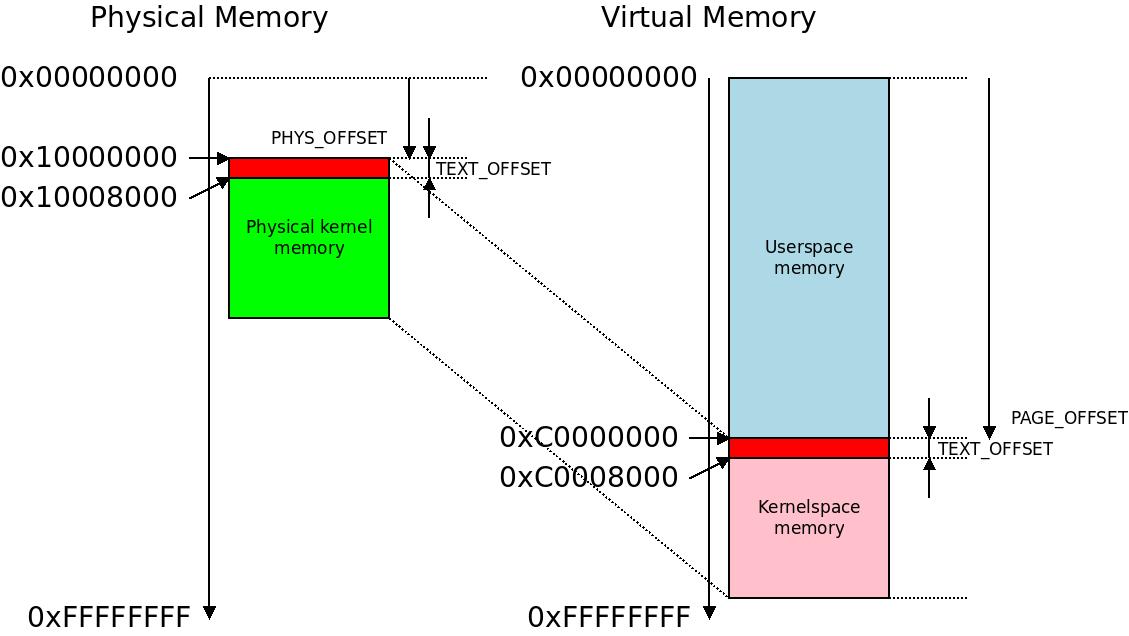 The
The 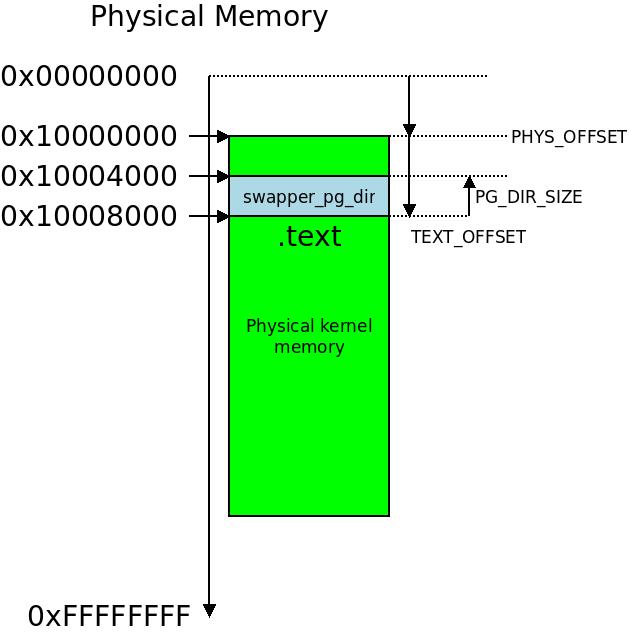 The swapper_pg_dir symbol will in our example reside 16KB (
The swapper_pg_dir symbol will in our example reside 16KB (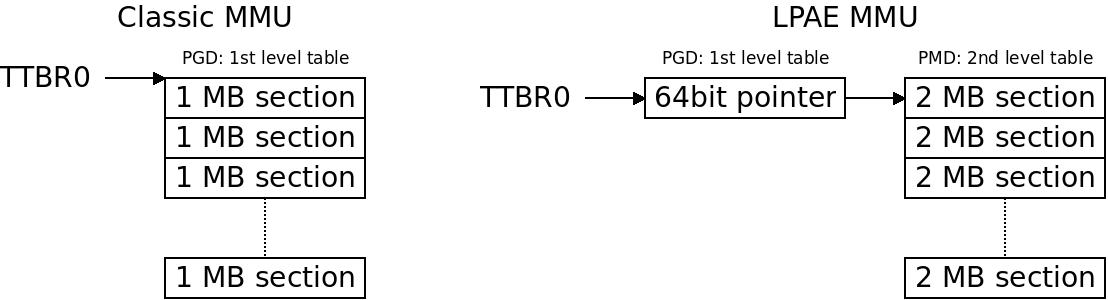 In the classic MMU we just point the MMU to a 1st level table with 1MB sections while for LPAE we need an intermediate level to get to the similar format with 2MB. The entries are called section descriptors.
In the classic MMU we just point the MMU to a 1st level table with 1MB sections while for LPAE we need an intermediate level to get to the similar format with 2MB. The entries are called section descriptors.
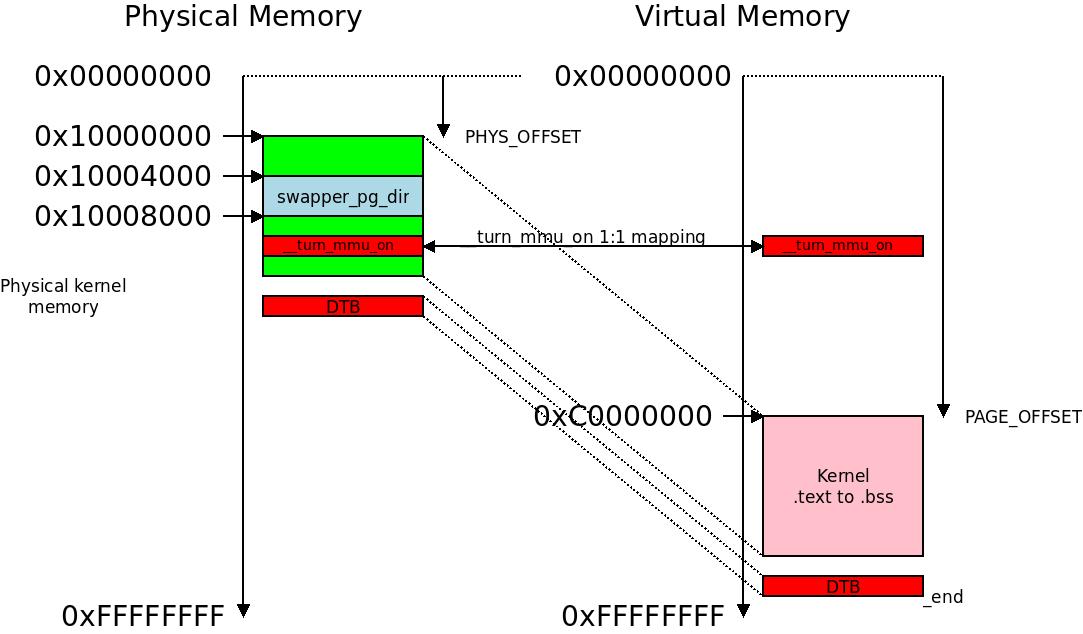 The initial page table swapper_pg_dir and the 1:1 mapped one-page-section __turn_mmu_on alongside the physical to virtual memory mapping at early boot. In this example we are not using LPAE so the initial page table is
The initial page table swapper_pg_dir and the 1:1 mapped one-page-section __turn_mmu_on alongside the physical to virtual memory mapping at early boot. In this example we are not using LPAE so the initial page table is 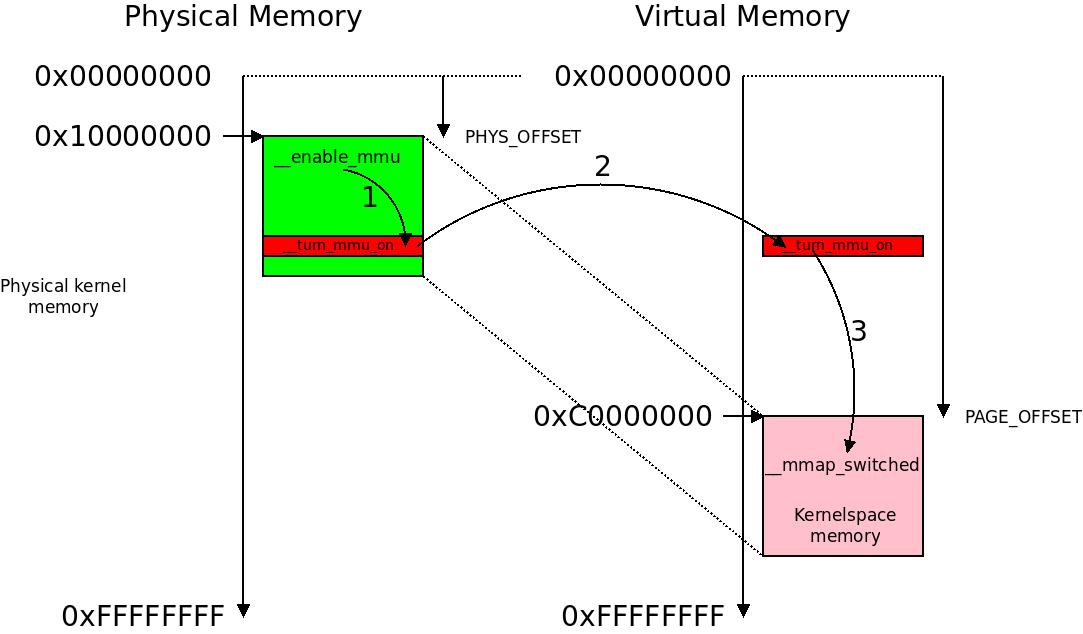 The little “dance” of the program counter as we switch execution from physical to virtual memory.
The little “dance” of the program counter as we switch execution from physical to virtual memory.