Setting Up the ARM32 Architecture, part 2
This is the continuation of Setting Up the ARM32 Architecture, part 1.
As a recap, we have achieved the following:
- We are executing in virtual memory
- We figured out how to get the execution context of the CPU from the init task with task ID 0 using the sp register and nothing else
- We have initialized the CPU
- We have identified what type of machine (ARM system) we are running on
- We have enumerated and registered the memory blocks available for the kernel to use with the primitive memblock memory manager
- We processed the early parameters earlyparams
- We have provided early fixmaps and early ioremaps
- We have identified lowmem and highmem bounds
Memory Blocks – Part 2
We now return to the list of memory available for the Linux kernel.
arm_memblock_init() in arch/arm/mm/init.c is called, resulting in a number of memory reservations of physical memory the Linux memory allocator can NOT use, given as physical start address and size. So we saw earlier that memblock stores a list of available blocks of memory, and in addition to that it can set aside reserved memory.
For example the first thing that happens is this:
memblock_reserve(__pa(KERNEL_START), KERNEL_END - KERNEL_START);
It makes perfect sense that the kernel cannot use the physical memory occupied by by the kernel – the code of the kernel we are executing. KERNEL_END is set to _end which we know from previous investigation to cover not only the TEXT segment but also BSS of the kernel, i.e. all the memory the kernel is using.
Next we call arm_mm_memblock_reserve() which will reserve the memory used by the kernel initial page table, also known as pg_swapper_dir. Would be unfortunate if we overwrite that with YouTube videos.
Finally we reserve the memory used by the device tree (at the moment I write this there is a patch pending to fix a bug here) and any other memory reservations defined in the device tree.
A typical example of a memory reservation in the device tree is if you have a special video ram (VRAM). The following would be a typical example:
reserved-memory {
#address-cells = <1>;
#size-cells = <1>;
ranges;
/* Chipselect 3 is physically at 0x4c000000 */
vram: vram@4c000000 {
/* 8 MB of designated video RAM */
compatible = "shared-dma-pool";
reg = <0x4c000000 0x00800000>;
no-map;
};
};
This specific memory block (taken from the Versatile Express reference design) will be outside of the physical RAM memory and not disturb any other allocations, but it uses the very same facility in the device tree: anything with compatible “shared-dma-pool” will be set aside for special use.
When chunks of common (non-special-purpose) RAM is set aside these chunks are referred to as “carveouts”. A typical use of such carveouts is media buffers for video and audio.
Next, before we have started to allocate any memory on the platform we set aside memory to be used for contiguous memory allocation (CMA) if this memory manager is in use. The CMA memory pool can be used for other things than contiguous memory, but we cannot have unmovable allocations in there, so we better flag this memory as “no unmoveable allocations in here” as soon as possible.
As CMA is so good at handling contiguous memory it will be used to handle the random carveouts and special memory areas indicated by “shared-dma-pool” as well. So be sure to select the Kconfig symbols CMA and CMA_DMA if you use any of these.
Next we call memblock_dump_all() which will show us nothing, normally. However if we pass the command line parameter memblock=debug to the kernel we will get a view of what things look like, first how much memory is available in total and how much is reserved in total for the things we outlined above, and then a detailed list of the memory available and set aside, similar to this:
MEMBLOCK configuration:
memory size = 0x08000000 reserved size = 0x007c1256
memory.cnt = 0x1
memory[0x0] [0x00000000-0x07ffffff], 0x08000000 bytes flags: 0x0
reserved.cnt = 0x3
reserved[0x0] [0x00004000-0x00007fff], 0x00004000 bytes flags: 0x0
reserved[0x1] [0x00008400-0x007c388b], 0x007bb48c bytes flags: 0x0
reserved[0x2] [0x00c38140-0x00c39f09], 0x00001dca bytes flags: 0x0
reserved[0x3] [0xef000000-0xefffffff], 0x01000000 bytes flags: 0x0
This is taken from the ARM Versatile reference platform and shows that we have one big chunk of memory that is 0x08000000 (128 MB) in size. In this memory we have chiseled out three reservations of in total 0x007C1256 (a bit more than 7 MB). The first reservation is the page table (swapper_pg_dir) the second is the kernel TEXT and BSS, the third is the DTB and the last reservation is the CMA pool of 16MB.
After this point, we know what memory in the system we can and cannot use: early memory management using memblock is available. This is a crude memory management mechanism that will let you do some rough memory reservations before the “real” memory manager comes up. We can (and will) call memblock_alloc() and memblock_phys_alloc() to allocate virtual and physical memory respectively.
If you grep the kernel for memblock_alloc() calls you will see that this is not a common practice: a few calls here and there. The main purpose of this mechanism is for the real memory manager to bootstrap itself: we need to allocate memory to be used for the final all-bells-and-whistles memory management: data structures to hold the bitmaps of allocated memory, page tables and so on.
At the end of this bootstrapping mem_init() will be called, and that in turn calls memblock_free_all() and effectively shuts down the memblock mechanism. But we are not there yet.
After this excursion among the memblocks we are back in setup_arch() and we call adjust_lowmem_bounds() a second time, as the reservations and carveouts in the device tree may have removed memory from underneath the kernel. Well we better take that into account. Redo the whole thing.
Setting up the paging
We now initialize the page table. early_ioremap_reset() is called, turning off the early ioremap facility (it cannot be used while the paging proper is being set up) and then we enable proper paging with the call to paging_init(). This call is really interesting and important: this is where we set up the system to perform the lower levels of proper memory management.
This is a good time to recap the inner workings of the ARM32 page tables before you move along. The relationship between kernel concepts such as PGD, PMD and PTE and the corresponding ARM level-1, level-2 and on LPAE level-3 page table descriptors need to be familiar.
The first thing we do inside paging_init() is to call prepare_page_table(). What it does is to go into the PGD and clear all the PMDs that are not in use by the kernel. As we know, the PGD has 4096 32bit/4-bytes entries on the classic ARM32 MMU grouped into 2048 PMDs and 512 64bit/8 byte entries on LPAE corresponding to one PMD each. Each of them corresponds to a 2MB chunk of memory. The action is going to hit the swapper_pg_dir at 0xC0004000 on classic MMUs or a combination of PGD pointers at 0xC0003000 and PMD pointers at 0xC0004000 on LPAE MMUs.
Our 1MB section mappings currently covering the code we are running and all other memory we use are first level page table entries, so these are covering 1 MB of virtual memory on the classic MMU and 2 MB of memory on LPAE systems. However the size we advance with is defined as PMD_SIZE which will always be 2 MB so the loop clearing the page PMDs look like so:
for (addr = 0; addr < PAGE_OFFSET; addr += PMD_SIZE)
pmd_clear(pmd_off_k(addr));
(Here I simplified the code by removing the execute-in-place (XIP) case.)
We advance one PMD_SIZE (2 MB) chunk at a time and clear all PMDs that are not used, here we clear the PMDs covering userspace up to the point in memory where the linear kernel mapping starts at PAGE_OFFSET.
We have stopped using sections of 1 MB or any other ARM32-specific level-1 descriptor code directly. We are using PMDs of size 2 MB and the generic kernel abstractions. We talk to the kernel about PMDs and not “level-1 descriptors”. We are one level up in the abstractions, removed from the mundane internals of the ARM32 MMU.
pmd_clear() will in practice set the entry to point at physical address zero and all MMU attributes will also be set to zero so the memory becomes non-accessible for read/write and any other operations, and then flush the translation lookaside buffer and the L2 cache (if present) so that we are sure that all this virtual memory now points to unaccessible zero – a known place. If we try to obtain an instruction or data from one of these addresses we will generate a prefect abort of some type.
One of the PMDs that get wiped out in this process is the two section-mapping PMDs that were 1-to1-mapping __turn_mmu_on earlier in the boot, so we swipe the floor free from some bootstrapping.
Next we clear all PMDs from the end of the first block of lowmem up until VMALLOC_START:
end = memblock.memory.regions[0].base + memblock.memory.regions[0].size;
if (end >= arm_lowmem_limit)
end = arm_lowmem_limit;
for (addr = __phys_to_virt(end); addr < VMALLOC_START; addr += PMD_SIZE)
pmd_clear(pmd_off_k(addr));
What happens here? We take the first memory block registered with the memblock mechanism handling physical memory, then we cap that off at arm_lowmem_limit which we saw earlier is in most cases set to the end of the highest memory block, which will mostly be the same thing unless we have several memory blocks or someone passed in command parameters reserving a lot of vmalloc space, so this procedure assumes that the kernel is loaded into the first available (physical) memory block, and we will then start at the end of that memory block (clearly above the kernel image) and clear all PMDs until we reach VMALLOC_START.
VMALLOC_START is the end of the virtual 1-to-1 mapping of the physical memory + 8 MB. If we have 512 MB of physical memory at physical address 0x00000000 then that ends at 0x1FFFFFFF and VMALLOC_START will be at 0x20000000 + PAGE_OFFSET + 0x00800000 = 0xE0800000. If we have 1 GB of physical memory VMALLOC_START will run into the highmem limit at 0xF0000000 and the end of the 1-to-1 physical mapping will naturally be there, so the VMALLOC_START will be at 0xF0800000 for anything with more 768 MB memory. The 8 MB between the end of lowmem and VMALLOC_START is a “buffer” to catch stray references.
For example if a system has 128 MB of RAM starting at 0x00000000 in a single memory block and the kernel zImage is 8MB in size and gets loaded into memory at 0x10008000-0x107FFFFF with the PGD (page global directory) at 0x10004000, we will start at address 0x20000000 translated to virtual memory 0xE0000000 and clear all PMDs for the virtual memory up until we reach 0xF0800000.
The physical memory in the memblock that sits above and below the start of the kernel, in this example the physical addresses 0x00000000-0x0FFFFFFF and 0x10800000-0x1FFFFFFF will be made available for allocation as we initialize the memory manager: we have made a memblock_reserve() over the kernel and that is all that will actually persist – memory in lowmem (above the kernel image) and highmem (above the arm_lowmem_limit, if we have any) will be made available to the memory allocator as well.
This code only initializes the PMDs, i.e. the entries in the first level of the page table, to zero memory with zero access to protect us from hurting ourselves.
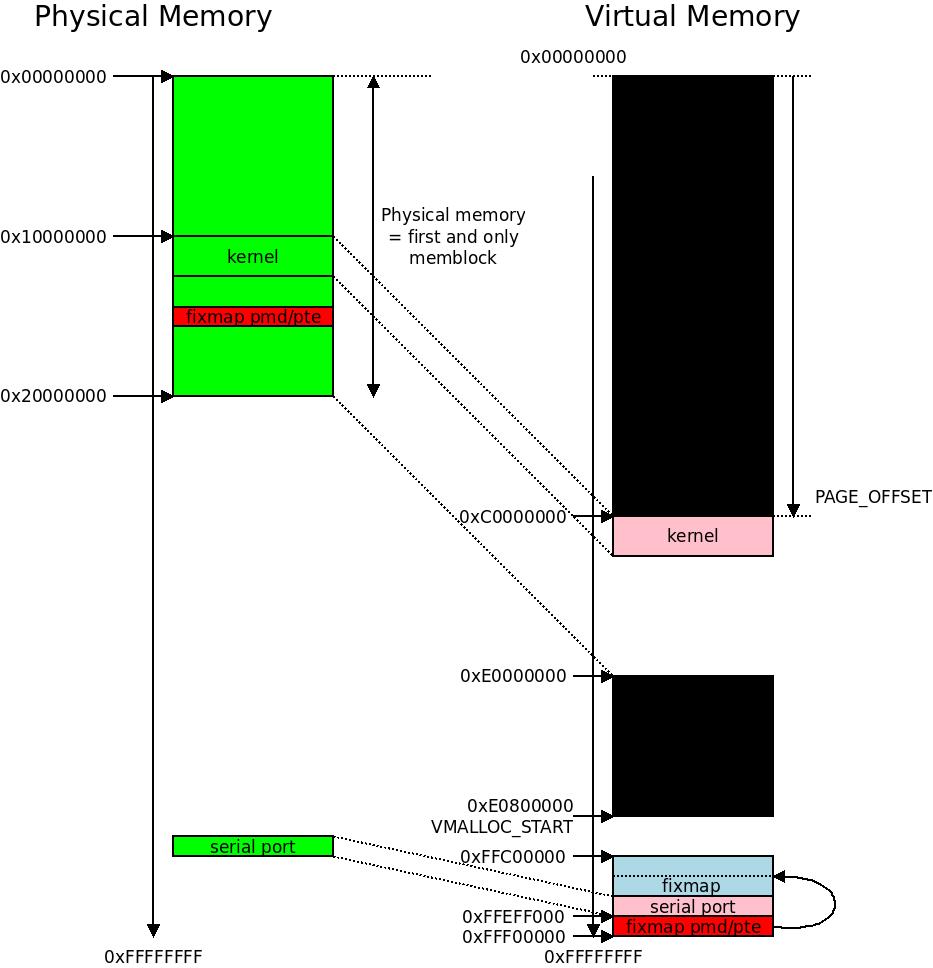 This image illustrates what happens when we initialize the PMDs (the picture is not to scale). The black blocks are the PMDs we clear, making them unavailable for any references for now. We have one block of physical memory from
This image illustrates what happens when we initialize the PMDs (the picture is not to scale). The black blocks are the PMDs we clear, making them unavailable for any references for now. We have one block of physical memory from 0x00000000-0x1FFFFFFF (512 MB) and we clear out from the end of that block in virtual memory until we reach VMALLOC_START.
Mapping lowmem
Next we call map_lowmem() which is pretty self-describing. Notice that we are talking about lowmem here: the linear kernelspace memory map that is accessed by adding or subtracting an offset from/to the physical or virtual memory address. We are not dealing with the userspace view of the memory at all, only the kernel view of the memory.
We round two physical address pointers to the start and end PMDs (we round on SECTION_SIZE, i.e. 1 MB bounds) of the executable portions of the kernel. The lower part of the kernel (typically starting at address 0xC0008000) is the executable TEXT segment so the start of this portion of the virtual memory is assigned to pointer kernel_x_start and kernel_x_end is put rounded up to the next section for the symbol __init_end, which is the end of the executable part of the kernel.
The BSS segment and other non-execuable segments are linked below the executable part of the kernel, so this is in the virtual memory above the executable part of the kernel.
Then we loop over all the memory blocks we have in the system and call create_mapping() where we first check the following conditions:
- If the end of the memblock is below the start of the kernel the memory is mapped as readable/writeable/executable
MT_MEMORY_RWX. This is a whole memory block up in userspace memory and similar. We want to be able to execute code up there. I honestly do not know why, but I can think about things such as small firmware areas that need to be executable, registered somewhere in a very low memblock. - If the start of the memblock is above
kernel_x_endthe memory is mapped as readable/writeable. No execution shall happen in the linear map above the executable kernel memory.
Next we reach the situation where the memblock is covering both the executable and the non-executable part of the kernel image. There is even a comment saying “this better cover the entire kernel” here: the whole kernel has to be inside one memory block under these circumstances or the logic will not work.
This is the most common scenario under all circumstances, such as my example with a single 128 MB physical memory block. Most ARM32 systems are like this.
We then employ the following pretty intuitive mapping:
- If the memblock starts below the executable part of the kernel
kernel_start_xwe chop off that part and map it as readable/writeable withMT_MEMORY_RW. - Then we map
kernel_x_starttokernel_x_endas readable/writeable/executable withMT_MEMORY_RWX. - Then we map the last part of the kernel above
kernel_x_endto the end of the memblock as readable/writeable withMT_MEMORY_RW.
 This illustrates how the memory above the kernel is readable/writeable, the upper part of the kernel image with the text segment is readable/writeable/executable while the lower .data and .bss part is just readable/writeable, then the rest of lowmem is also just readable writable. In this example we have 128MB (
This illustrates how the memory above the kernel is readable/writeable, the upper part of the kernel image with the text segment is readable/writeable/executable while the lower .data and .bss part is just readable/writeable, then the rest of lowmem is also just readable writable. In this example we have 128MB (0x20000000) of memory and the in the kernel image lowmem is mapped 0x00000000 -> 0xB0000000, 0x10000000 -> 0xC0000000 and 0x20000000 -> 0xD0000000. The granularity may require individual 4K pages so this will use elaborate page mapping.
The executable kernel memory is also writable because the PGD is in the first PMD sized chunk here – we sure need to be able to write to that – and several kernel mechanisms actually rely on being able to runtime-patch the executable kernel, even if we have already finalized the crucial physical-to-virtual patching. One example would be facilities such as ftrace.
Everything that fits in the linearly mapped lowmem above and below the kernel will be readable and writable by the kernel, which leads to some optimization opportunities – especially during context switches – but also to some problems, especially regarding the highmem. But let’s not discuss that right now.
map_lowmem() will employ create_mapping() which in turn will find out the PGD entries (in practice, on a classical MMU in this case that will be one entry of 32 bits/4 bytes in the level-1 page table) for the address we pass in (which will be PMD-aligned at 2 MB), and then call alloc_init_p4d() on that pgd providing the start and end address. We know very well that ARM32 does not have any five- or four-level page tables but this is where the generic nature of the memory manager comes into play: let’s pretend we do. alloc_init_p4d() will traverse the page table ladder with alloc_init_pud() (we don’t use that either) and then alloc_init_pmd() which we actually use, and then at the end if we need it alloc_init_pte().
What do I mean by “if we need it”? Why would we not allocate PTEs, real page-to-page tables for every 0x1000 chunk of physical-to-virtual map?
It’s because allocinitpmd() will first see if the stuff we map is big enough to use one or more section mappings – i.e. just 32 bits/4 bytes in the PGD at 0xC0004000-somewhere to map the memory. In our case that will mostly be the case! The kernel will if possible remain section mapped, and we call __map_init_section() which will create and write the exact same value into the PGD as we had put in there before – well maybe it was all executable up onto this point, so at least some small bits will change. But we try our best to use the big and fast section maps if we can without unnecessarily creating a myriad of PTE-level objects that turn into level-2 descriptors that need to be painstakingly traversed.
However on the very last page of the executable part of the kernel and very first page of the data segments it is very likely that we cannot use a section mapping, and for the first time the generic kernel fine-granular paging using 4 KB pages will kick in to provide this mapping. We learnt before that the linker file has been carefully tailored to make sure that each segment of code starts on an even page, so we know that we can work at page granularity here.
In create_mapping(), if the start and end of the memory we try to map is not possible to fit perfectly into a section, we will call alloc_init_pte() for the same address range. This will allocate and initialize a PTE, which is the next level down in the page table hierarchy.
phys_addr_t start, end;
struct map_desc map;
map.pfn = __phys_to_pfn(start);
map.virtual = __phys_to_virt(start);
map.length = end - start;
map.type = MT_MEMORY_RWX;
create_mapping(&map);
A typical case of creating a mapping with create_mapping(). We set the page frame number (pfn) to the page we want to start the remapping at, then the virtual address we want the remapping to appear at, and the size and type of the remapping, then we call create_mapping().
So Let’s Map More Stuff
We now know what actually happens when we call create_mapping() and that call is used a lot in the early architecture set-up. We know that map_lowmem() will chop up the border between the executable and non-executable part of the kernel using the just described paging layout of our MMU using either the classic complicated mode or the new shiny LPAE mode.
The early section mappings we put over the kernel during boot and start of execution from virtual memory are now gone. We have overwritten them all with the new, proper mappings, including the very memory we executed the remappings in. Nothing happens, but the world is now under generic kernel memory management control. The state of the pages is, by the way, maintained in the page tables themselves.
If we create new PTEs these will be allocated into some new available memory page as well using alloc(). At this point that means that the memblock allocator will be used, since the proper memory management with kmalloc() is not yet operational. The right type of properties (such as read/write/execute or other MT_* characteristics) will be used however so we could say that we have a “halfway” memory manager: the hardware is definitely doing the right thing now, and the page tables are manipulated the right way using generic code.
map_lowmem() is done. We call memblock_set_current_limit(arm_lowmem_limit) because from now on we only want memblock allocations to end up in lowmem proper, we have just mapped it in properly and all. In most cases this is the same as before, but in some corner cases we cannot put this restriction until now.
We remap the contiguous memory allocation area if CMA is in use, again using all the bells and whistles of the kernel’s generic memory manager. MMU properties for DMA memory is set to MT_MEMORY_DMA_READY which is very close to normal read/writeable memory.
Next we shutdown the fixmap allocations. The remapped memory that was using fixmaps earlier gets mapped like the kernel itself and everything else using create_mapping() instead of the earlier hacks poking directly into the page tables. They are all one page each and uses MT_DEVICE, i.e. write-through, uncached registers of memory-mapped I/O, such as used by the earlyconsole UART registers.
Next we set up some special mappings in devicemaps_init() that apart from the early ones we just reapplied add some new ones, i.e. some not-so-early mappings. They are mostly not devices either so the function name is completely misleading. The function is called like this because it at one point calls the machine-specific ->map_io() callback for the identified machine descriptor, which on pure device tree systems isn’t even used.
Inside devicemaps_init() We clear some more PMDs. Now we start at VMALLOC_START: the place where we previously stopped the PMD clearing, advancing 2 MB at a time up to FIXADDR_TOP which is the location of the fixmaps. Those have been redefined using the generic kernel paging engine, but they are still there, so we must not overwrite them.
Next follow some special mappings, then we get to something really interesting: the vectors.
Setting Up and Mapping the Exception Vector Table
The vector table is a page of memory where the ARM32 CPUs will jump when an exception occurs. Exceptions vectors can be one of:
- Reset exception vector: the address the PC is set to if the RESET line to the CPU is asserted.
- Undefined instruction exception vector: the address we jump to if an undefined instruction is executed. This is used for example to emulate floating point instructions if your CPU does not have them.
- Software Interrupt (SWI) exception vector: also called a “trap”, is a way to programmatically interrupt the program flow and execute a special handler. In Linux this is used by userspace programs to execute system calls: to call on the kernel to respond to needs of a userspace process.
- Prefetch abort exception vector: this happens when the CPU tries to fetch an instruction from an illegal address, such as those addresses where we have cleared the level-1 page table descriptor (PMD) so there is no valid physical memory underneath. This is also called a page fault and is used for implementing demand paging, a central concept in Unix-like operating systems.
- Data abort exception vector: same thing but the CPU is trying to fetch data rather than an instruction. This is also used for demand paging.
- Address exception vector: this is described in the source as “this should never happen” and some manuals describe it as “unused” or “reserved”. This is actually an architectural leftover from the ARM26 (ARMv1, v2, v3) no longer supported by Linux. In older silicon the virtual address space was 26 bits rather than the 32 bits in later architectures, and this exception would be triggered when an address outside the 26 bit range was accessed. (This information came from LWN reader farnz as a reply to this article.) On full 32-bit silicon it should indeed never happen.
- Interrupt Request IRQ exception vector: the most natural type of exception in response to the IRQ line into the CPU. In later ARM32 CPUs this usually comes from the standard GIC (Generic Interrupt Controller) but in earlier silicon such as ARMv4 or ARMv5 some custom interrupt controller is usually connected to this line. The origin of the line was a discrete signal routed out on the CPU package, but in modern SoCs these are usually synthesized into the same silicon so the line is not visible to the outside, albeit the concept is the same.
- Fast Interrupt Request FIQ exception vector: this is mostly unused in Linux, and on ARMv7 silicon often used to trap into the secure world interrupt handlers and thus not even accessible by the normal world where Linux is running.
These eight vectors in this order is usually all we ever need on any ARM32 CPU. They are one 32bit word each, so the PC is for example set at address 0xFFFF0000 when reset occurs and whatever is there is executed.
The way the vector table/page works is that the CPU will store the program counter and processor state in internal registers and put the program counter at the corresponding vector address. The vector table can be put in two locations in memory: either at address 0x00000000 or address 0xFFFF0000. The location is selected with a single bit in the CP15 control register 1. Linux supports putting the vectors in either place with a preference for 0xFFFF0000. Using address 0x00000000 is typically most helpful if the MMU is turned off and you have a 1-to-1 mapping to a physical memory that starts at address 0x00000000. If the MMU is turned on, which it is for us, the address used is the virtual one, even the vector table goes through MMU translation, and it is customary to use the vectors high up in memory, at address 0xFFFF0000.
As we noted much earlier, each exception context has its own copy of the sp register and thus is assigned an exception-specific stack. Any other registers need to be spooled out and back in by code before returning from the exception.
 The ARM32 exception vector table is a 4KB page where the first 8 32-bit words are used as vectors. The address exception should not happen and in some manuals is described as “unused”. The program counter is simply set to this location when any of these exceptions occur. The remainder of the page is “poisoned” with the word
The ARM32 exception vector table is a 4KB page where the first 8 32-bit words are used as vectors. The address exception should not happen and in some manuals is described as “unused”. The program counter is simply set to this location when any of these exceptions occur. The remainder of the page is “poisoned” with the word 0xE7FDDEF1.
ARM Linux uses two consecutive pages of memory for exception handling: the first page is the vectors, the second page is called stubs. The vectors will typically be placed at 0xFFFF0000 and the stubs at the next page at 0xFFFF1000. If you use the low vectors these will instead be at 0x00000000 and 0x00001000 respectively. The actual physical pages backing these locations are simply obtained from the rough memblock allocator using memblock_alloc(PAGE_SIZE * 2).
The stubs page requires a bit of explanation: since each vector is just 32 bits, we simply cannot just jump off to a desired memory location from it. Long jumps require many more bits than 32! Instead we do a relative jump into the next page, and either handle the whole exception there (if it’s a small thing) or dispatch by jumping to some other kernel code. The whole vector and stubs code is inside the files arch/arm/kernel/entry-armv.S and arch/arm/kernel/traps.c. (The “armv” portion of the filename is misleading, this is used for pretty much all ARM32 machines. “Entry” means exception entry point.)
The vector and stub pages is set up in the function early_trap_init() by first filling the page with the 32bit word 0xE7FDDEF1 which is an undefined instruction on all ARM32 CPUs. This process is called “poisoning”, and makes sure the CPU locks up if it ever would put the program counter here. Poisoning is done to make sure wild running program counters stop running around, and as a security vulnerability countermeasure: overflow attacks and other program counter manipulations often tries to lead the program counter astray. Next we copy the vectors and stubs to their respective pages.
The code in the vectors and stubs has been carefully tailored to be position-independent so we can just copy it and execute it wherever we want to. The code will execute fine at address 0xFFFF0000-0xFFFF1FFF or 0x00000000-0x00001FFF alike.
You can inspect the actual vector table between symbols __vector_start and __vector_end at the end of entry-armv.S: there are 8 32-bit vectors named vector_rst, vector_und … etc.
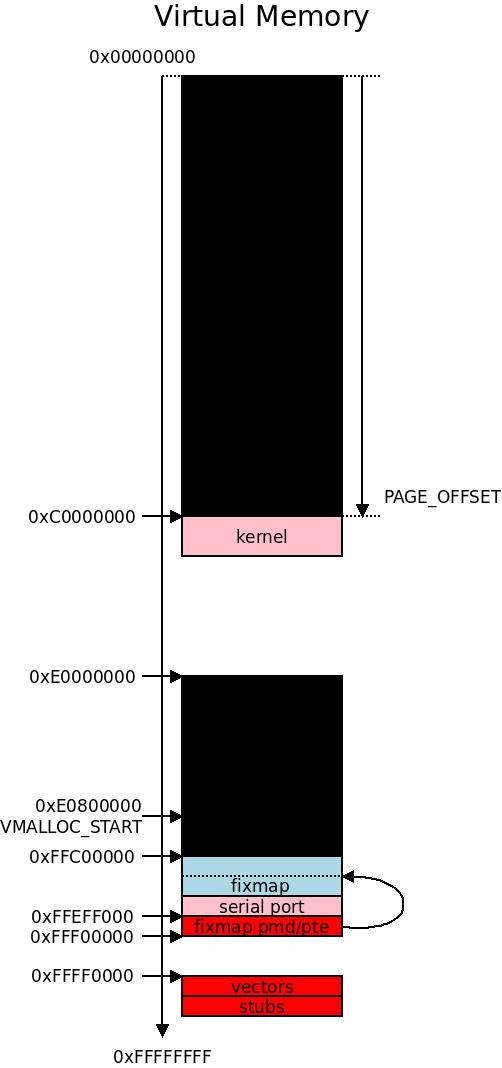 We cleared some more PMDs between
We cleared some more PMDs between VMALLOC_START and the fixmaps, so now the black blocks are bigger in the virtual memory space. At 0xFFFF0000 we install vectors and at 0xFFFF1000 we install stubs.
We will not delve into the details of ARM32 exception handling right now: it will suffice to know that this is where we set it up, and henceforth we can deal with them in the sense that ARM32 will be able to define exception handlers after this point. And that is pretty useful. We have not yet defined any generic kernel exception or interrupt interfaces.
The vectors are flushed to memory and we are ready to roll: exceptions can now be handled!
At the end of devicemaps_init() we call early_abt_enable() which enables us to handle some critical abort exceptions during the remaining start-up sequence of the kernel. The most typical case would be a secondary CPU stuck in an abort exception when brought online, we need to cope with that and recover or it will bring the whole system down when we enable it.
The only other notable thing happening in devicemaps_init() is a call to the machine descriptor-specific .map_io() or if that is undefined, to debug_ll_io_init(). This used to be used to set up fixed memory mappings of some device registers for the machine, since at this point the kernel could do that properly using create_mapping(). Nowadays, using device trees, this callback will only be used to remap a debug UART for LL_DEBUG (all other device memory is remapped on-demand) which is why the new function name debug_ll_io_init() which isn’t even using the machine descriptor is preferred.
Make no mistake: DEBUG_LL is already assuming a certain virtual address for the UART I/O-port up until this point and it better remain there. We mapped that much earlier in head.S using a big fat section mapping of 1MB physical-to-virtual memory.
What happens in debug_ll_io_init() is that the same memory window is remapped properly with create_mapping() using a fine-granular map of a single page of memory using the right kernel abstractions. We obtain the virtual address for the UART using the per-serialport assembly macro addruart from the assembly file for the corresponding UART in arch/arm/include/debug/*.
This will overwrite the level-1 section mapping descriptor used for debug prints up until this point with a proper level-1 to level-2 pointer using PMDs and PTEs.
Initialzing the Real Memory Manager
Back in paging_init() we call kmap_init() that initialize the mappings used for highmem and then tcm_init() which maps some very tiny on-chip RAMs if we have them. The TCM (tightly coupled memory) is small SDRAMs that are as fast as cache, that some vendors synthesize on their SoCs.
Finally we set top_pmd to point at address 0xFFFF0000 (the vector space) and we allocate a page called the empty_zero_page which will be a page filled with zeroes. This is sometimes very helpful for the kernel when referencing a “very empty page”.
We call bootmem_init() which brings extended memblock page handling online: it allows resizing of memblock allocations, finds the lowest and highest page frame numbers pfns, performs an early memory test (if compiled in) and initializes sparse memory handling in the generic virtual memory manager.
We then chunk the physical memory into different memory zones with the final call to free_area_init() providing the maximum page frame numbers for the different memory zones: ZONE_DMA, ZONE_NORMAL, and ZONE_HIGHMEM are used on ARM32. The zones are assumed to be consecutive in physical memory, so only the maximum page frame numbers for each zone is given.
ZONE_DMAis for especially low physical memory that can be accessed by DMA by some devices. There are machines with limitations on which addresses some devices can access when performing DMA bus mastering, so these need special restrictions on memory allocation.ZONE_NORMALis what we refer to as lowmem on ARM32: the memory that the kernel or userspace can use for anything.ZONE_HIGHMEMis used with the ARM32 definition of highmem , which we have discussed in detail above: memory physically above the 1-to-1-mapped lowmem.
After returning from free_area_init() the generic kernel virtual memory pager is finally initialized. The memory management is not yet online: we cannot use kmalloc() and friends, but we will get there. We still have to use memblock to allocate memory.
We call request_standard_resources(), which is a call to register to the kernel what purpose specific memory areas have. Here we loop over the memblocks and request them as System RAM if nothing else applies. The resource request facility is hierarchical (resources can be requested inside resources) so the kernel memory gets requested inside the memory block where it resides. This resource allocation provides the basic output from the file /proc/iomem such as the location of the kernel in memory. This facility is bolted on top of the actual memory mapping and just works as an optional protection mechanism.
Finalizing Architecture Setup
We are getting close to the end of ARM32:s setup_arch() call.
If the machine descriptor has a restart hook we assign the global function pointer arm_pm_restart to this. Nominally drivers to restart modern platforms should not use this: they should provide a restart handler in drivers/power/reset/* registering itself using register_restart_handler(), but we have a bit of legacy code to handle restarts, and that will utilize this callback.
Next we unflatten the device tree, if the machine uses this, which all sufficiently modern ARM32 machines should. The device tree provided from boot is compact, binary and read only, so we need to process it so that boot code and device drivers can traverse the device tree easily. An elaborate data structure is parsed out from the device tree blob and allocated into free pages, again using the crude memblock allocator.
So far we only used very ad hoc device tree inspection to find memory areas and memory reservations.
Now we can inspect the device tree in a more civilized manner to find out some very basic things about the platform. The first thing we will actually do is to read the CPU topology information out of the device tree and build a list of available CPUs on the system. But that will happen later on during boot.
Finally, and lastly, we check if the machine has defined ->init_early() and need some other early work. If it does then we call this callback. Else we are done with setup_arch().
After this we return to the function start_kernel() in init/main.c again, where we will see how the kernel builds zones of the memory blocks, initializes the page allocator and finally gets to call mm_init() which brings the proper memory management with kmalloc() and friends online. We will set up SMP, timekeeping and call back into the architecture to finalize the deal.
But this is all a topic for another time.