The ARM32 Scheduling and Kernelspace/Userspace Boundary
As of recent I needed to understand how the ARM32 architecture switches control of execution between normal, userspace processes and the kernel processes, such as the init task and the kernel threads. Understanding this invariably involves understanding two aspects of the ARM32 kernel:
- How tasks are actually scheduled on ARM32
- How the kernelspace and userspace are actually separated, and thus how we move from one to the other
This is going to require knowledge from some other (linked) articles and a good understanding of ARM32 assembly.
Terminology
With tasks we mean processes, threads and kernel threads. The kernel scheduler see no major difference between these, they are schedulable entities that live on a certain CPU.
Kernel threads are the easiest to understand: in the big computer program that is the kernel, different threads execute on behalf of managing the kernel. They are all instantiated by a special thread called kthreadd — the kernel thread daemon. They exist for various purposes, one is to provide process context to interrupt threads, another to run workqueues such as delayed work and so on. It is handy for e.g. kernel drivers to be able to hand over execution to a process context that can churn on in the background.
Processes in userspace are in essence executing computer programs, or objects with an older terminology, giving the origin of expressions such as object file format. The kernel will start very few such processes, but modprobe and init (which always has process ID 1) are notable exceptions. Any other userspace processes are started by init. Processes can fork new processes, and it can also create separate threads of execution within itself, and these will become schedulable entities as well, so a certain process (executing computer program) can have concurrency within itself. POSIX threads is usually the way this happens and further abstractions such as the GLib GThread etc exist.
 A pie chart of tasks according to priority on a certain system produced using CGFreak shows that from a scheduler point of view there are just tasks, any kernel threads or threads spawn from processes just become schedulable task entities.
A pie chart of tasks according to priority on a certain system produced using CGFreak shows that from a scheduler point of view there are just tasks, any kernel threads or threads spawn from processes just become schedulable task entities.
The userspace is the commonplace name given to a specific context of execution where we execute processes. What defines this context is that it has its own memory context, a unique MMU table, which in the ARM32 case gives each process a huge virtual memory to live in. Its execution is isolated from the kernel and also from other processes, but not from its own threads (typically POSIX threads). To communicate with either the kernel or other userspace processes, it needs to use system calls “syscalls” or emit or receive signals. Both mechanisms are realized as software interrupts. (To communicate with its own spawn threads, shortcuts are available.)
The kernelspace conversely is the context of execution of the operating system, in our case Linux. It has its own memory context (MMU table) but some of the kernel memory is usually also accessible by the userspace processes, and the virtual memory space is shared, so that exceptions can jump directly into kernel code in virtual memory, and the kernel can directly read and write into userspace memory. This is done like so to facilitate quick communication between the kernel and userspace. Depending on the architecture we are executing Linux on, executing in kernelspace is associated with elevated machine privileges, and means the operating system can issue certain privileged instructions or otherwise access some certain restricted resources. The MMU table permissions protects kernel code from being inspected or overwritten by userspace processes.
Background
This separation, along with everything else we take for granted in modern computers and operating systems was created in the first time-sharing systems such as the CTSS running on the IBM 700/7000 series computers in the late 1950ies. The Ferranti Atlas Computer in 1962-1967 and its supervisor program followed shortly after these. The Atlas invented nifty features such as virtual memory and memory-mapped I/O, and was of course also using time-sharing. As can be easily guessed, these computers and operating systems (supervisors) designs inspired the hardware design and operating system designs of later computers such as the PDP-11, where Unix began. This is why Unix-like operating systems such as Linux more or less take all of these features and concepts for granted.
The idea of a supervisor or operating system goes deep into the design of CPUs, so for example the Motorola 68000 CPU had three function code pins routed out on the package, FC2, FC1 and FC0 comprising three bits of system mode, four of these bit combinations representing user data, user program, supervisor data and supervisor program. (These modes even reflect the sectioning of program and supervisor objects into program code or TEXT segments and a DATA segments.) In the supervisor mode, FC2 was always asserted. This way physical access to memory-mapped peripherals could be electronically constrained to access only from supervisor mode. Machines such as the Atari ST exploited this possibility, while others such as the Commodore Amiga did not.
All this said to give you a clear idea why the acronym SVC as in Supervisor Call is used rather than e.g. operating system call or kernel call which would have been more natural. This naming is historical.
Execution Modes or Levels
We will restrict the following discussion to the ARMv4 and later ARM32 architectures which is what Linux supports.
When it comes to the older CPUs in the ARMv4, ARMv5 and ARMv6 range these have a special supervisor mode (SVC mode) and a user mode, and as you could guess these two modes are mapped directly to kernelspace and userspace in Linux. In addition to this there are actually 5 additional exception modes for FIQ, IRQ, system mode, abort and undefined, so 7 modes in total! To cut a long story short, all of the modes except the user mode belong to kernelspace.
Apart from restricting certain instructions, the only thing actually separating the kernelspace from userspace is the MMU, which is protecting kernelspace from userspace in the same way that different userspace processes are protected from each other: by using virtual memory to hide physical memory, and in the cases where it is not hidden: using protection bits in the page table to restrict access to certain memory areas. The MMU table can naturally only be altered from supervisor mode and this way it is clear who is in control.
The later versions of the ARM32 CPU, the ARMv7, add some further and an even deeper secure monitor or just monitor mode.
For reference, these modes in the ARMv8 architecture correspond to “privilege levels”. Here the kernelspace execute at exception level EL1, and userspace at exception level EL0, then there are further EL2 and EL3 “higher” privilege levels. EL2 is used for hypervisor (virtualization) and EL3 is used for a secure monitor that oversee the switch back and forth to the trusted execution environment (TEE), which is a parallel and different operating environment, essentially like a different computer: Linux can interact with it (as can be seen in drivers/tee in the kernel) but it is a different thing than Linux entirely.
These higher privilege levels and the secure mode with its hypervisor and TEE are not always used and may be dormant. Strictly speaking, the security and virtualization functionality is optional, so it is perfectly fine to fabricate ARMv7 silicon without them. To accompany the supervisor call (SVC) on ARMv7 a hypervisor call (HVC) and a secure monitor call (SMC) instruction was added.
Exceptional Events
We discussed that different execution modes pertain to certain exceptions. So let's recap ARM32 exceptions.
As exceptions go, these happen both in kernelspace and userspace, but they are always handled in kernelspace. If that userspace process for example divides by zero, an exception occurs that take us into the kernel, all the time pushing state onto the stack, and resuming execution inside the kernel, which will simply terminate the process over this. If the kernel itself divides by zero we get a kernel crash since there is no way out.
The most natural exception is of course a hardware interrupt, such as when a user presses a key or a hard disk signals that a sector of data has been placed in a buffer, or a network card indicates that an ethernet packet is available from the interface.
Additionally, as mentioned previously, most architectures support a special type of software exception that is initiated for carrying out system calls, and on ARM and Aarch64 that is what is these days called the SVC (supervisor call) instruction. This very same instruction — i.e. with the same binary operation code — was previously called SWI (software interrupt) which makes things a bit confusing at times, especially when reading old documentation and old code, but the assembly mnemonics SVC and SWI have the same semantic. For comparison on m68k this instruction is named TRAP, on x86 there is the INT instruction and RISC-V has the SBI (supervisor binary interface) call.
In my article about how the ARM32 architecture is set up I talk about the exception vector table which is 8 32bit pointers stored in virtual memory from 0xFFFF0000 to 0xFFFF0020 and it corresponds roughly to everything that can take us from kernelspace to userspace and back.
The transitions occurs at these distinct points:
- A hardware RESET occurs. This is pretty obvious: we need to abort all user program execution, return to the kernel and take everything offline.
- An undefined instruction is encountered. The program flow cannot continue if this happens and the kernel has to do something about it. The most typical use for this is to implement software fallback for floating-point arithmetic instructions that some hardware may be lacking. These fallbacks will in that case be implemented by the kernel. (Since doing this with a context switch and software fallback in the kernel is expensive, you would normally just compile the program with a compiler that replace the floating point instructions with software fallbacks to begin with, but not everyone has the luxury of source code and build environment available and have to run pre-compiled binaries with floating point instructions.)
- A software interrupt occurs. This is the most common way that a userspace application issues a system call (supervisor call) into the operating system. As mentioned, on ARM32 this is implemented by the special SVC (aka SWI) instruction that passes a 1-byte parameter to the software interrupt handler.
- A prefetch abort occurs. This happens when the instruction pointer runs into unpaged memory, and the virtual memory manager (mm) needs to page in new virtual memory to continue execution. Naturally this is a kernel task.
- A data abort occurs. This is essentially the same as the prefetch abort but the program is trying to access unpaged data rather than unpaged instructions.
- An address exception occurs. This doesn't happen on modern ARM32 CPUs, because the exception is for when the CPU moves outside the former 26bit address space on ARM26 architectures that Linux no longer supports.
- A hardware interrupt occurs – since the operating system handles all hardware, naturally whenever one of these occur, we have to switch to kernel context. The ARM CPUs have two hardware interrupt lines: IRQ and FIQ. Each can be routed to an external interrupt controller, the most common being the GIC (Global Interrupt Controller) especially for multicore systems, but many ARM systems use their own, custom interrupt controllers.
- A fault occurs such as through division by zero or other arithmetic fault – the CPU runs into an undefined state and has no idea how to recover and continue. This is also called a processor abort.
That's all. But these are indeed exceptions. What is the rule? The computer programs that correspond to the kernel and each userspace process have to start somewhere, and then they are excecuted in time slices, which means that somehow they get interrupted by one of these exceptions and preempted, a procedure that in turn invariably involves transitions back and forth from userspace to kernelspace and back into userspace again.
So how does that actually happen? Let's look at that next.
Entering Kernelspace
Everything has a beginning. I have explained in a previous article how the kernel bootstraps from the function start_kernel() in init/main.c and sets up the architecture including virtual memory to a point where the architecture-neutral parts of the kernel starts executing.
Further down start_kernel() we initialize the timers, start the clocksource (the Linux system timeline) and initialize the scheduler so that process scheduling can happen. But nothing really happens, because there are no processes. Then the kernel reaches the end of the start_kernel() function where arch_call_rest_init() is called. This is in most cases a call to rest_init() in the same file (only S390 does anything different) and that in turn actually initializes some processes:
pid = user_mode_thread(kernel_init, NULL, CLONE_FS);
(...)
pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);
We create separate threads running the in-kernel functions kernel_init and kthreadd, which is the kernel thread daemon which in turn spawns all kernel threads.
The user_mode_thread() or kernel_thread() calls create a new processing context: they both call kernel_clone() which calls copy_process() with NULL as first argument, meaning it will not actually copy any process but instead create a new one. It will create a new task using dup_task_struct() passing current as argument, which is the init task and thus any new task is eventually derived from the compiled-in init task. Then there is a lot of cloning going on, and we reach copy_thread() which calls back into the architecture to initialize struct thread_info for the new task. This is a struct we will look at later, but notice one thing, and that is that when a new kernel or user mode thread is created like this (with a function such as kernel_init passed instead of just forking), the following happens:
memset(childregs, 0, sizeof(struct pt_regs));
thread->cpu_context.r4 = (unsigned long)args->fn_arg;
thread->cpu_context.r5 = (unsigned long)args->fn;
childregs->ARM_cpsr = SVC_MODE;
(...)
thread->cpu_context.pc = (unsigned long)ret_from_fork;
fn_arg will be NULL in this case but fn is kernel_init or kthreadd. And we execute in SVC_MODE which is the supervisor mode: as the kernel. Also user mode threads are initialized as supervisor mode tasks to begin with, but it will eventually modify itself into a userspace task. Setting the CPU context to ret_from_fork will be significant, so notice this!
Neither of the functions kernel_init or kthreadd will execute at this point! We will just return. The threads are initialized but nothing is scheduled yet: we have not yet called schedule() a single time, which means nothing happens, because nothing is yet scheduled.
kernel_init is a function in the same file that is as indicated will initialize the first userspace process. If you inspect this function you will see that it keeps executing some kernel code for quite a while: it waits for kthreadd to finish initalization so the kernel is ready for action, then it will actually do some housekeeping such as freeing up the kernel initmem (functions tagged __init) and only then proceed to run_init_process(). As indicated, this will start the init process using kernel_execve(), usually /sbin/init which will then proceed to spawn all usermode processes/tasks. kernel_execve() will check for supported binary formats and most likely call the ELF loader to process the binary and page in the file into memory from the file system etc. If this goes well, it will end with a call to the macro START_THREAD() which in turn wraps the ARM32-specific start_thread() which will, amongst other things, do this:
regs->ARM_cpsr = USR_MODE;
(...)
regs->ARM_pc = pc & ~1;
So the new userspace process will get pushed into userspace mode by the ELF loader, and that will also set the program counter to wherever the ELF file is set to execute. regs->ARM_cpsr will be pushed into the CPSR register when the task is scheduled, and we start the first task executing in userspace.
kthreadd on the other hand will execute a perpetual loop starting other kernel daemons as they are placed on a creation list.
But as said: neither is executing.
In order to actually start the scheduling we call schedule_preempt_disabled() which will issue schedule() with preemption disabled: we can schedule tasks, and they will not interrupt each other (preempt) in fine granular manner, so the scheduling is more “blocky” at this point. However: we already have the clockevent timer running so that the operating system is now ticking, and new calls to the main scheduler callbacks scheduler_tick() and schedule() will happen from different points in future time, at least at the system tick granularity (HZ) if nothing else happens. We will explain more about this further on in the article.
Until this point we have been running in the context of the Linux init task which is a elusive hard-coded kernel thread with PID 0 that is defined in init/init_task.c and which I have briefly discussed in a previous article. This task does not even appear in procfs in /proc.
As we call schedule(), the kernel init task will preempt and give way to kthreadd and then to the userspace init process. However when the scheduler again schedules the init task with PID 0, we return to rest_init(), and we will call cpu_startup_entry(CPUHP_ONLINE) and that function is in kernel/sched/idle.c and looks like this:
void cpu_startup_entry(enum cpuhp_state state)
{
arch_cpu_idle_prepare();
cpuhp_online_idle(state);
while (1)
do_idle();
}
That's right: this function never returns. Nothing ever breaks out of the while(1) loop. All that do_idle() does is to wait until no tasks are scheduling, and then call down into the cpuidle subsystem. This will make the CPU “idle” i.e. sleep, since nothing is going on. Then the loop repeats. The kernel init task, PID 0 or “main() function” that begins at start_kernel() and ends here, will just try to push down the system to idle, forever. So this is the eventual fate of the init task. The kernel has some documentation of the inner loop that assumes that you know this context.
Let's look closer at do_idle() in the same file, which has roughly this look (the actual code is more complex, but this is the spirit of it):
while (!need_resched()) {
local_irq_disable();
enter_arch_idle_code();
/* here a considerable amount of wall-clock time can pass */
exit_arch_idle_code();
local_irq_enable();
}
(...)
schedule_idle();
This will spin here until something else needs to be scheduled, meaning the init task has the TIF_NEED_RESCHED bit set, and should be preempted. The call to schedule_idle() soon after exiting this loop makes sure that this rescheduling actually happens: this calls right into the scheduler to select a new task and is a variant of the more generic schedule() call which we will see later.
We will look into the details soon, but we see the basic pattern of this perpetual task: see if someone else needs to run else idle and when someone else wants to run, stop idling and explicitly yield to whatever task was waiting.
Scheduling the first task
So we know that schedule() has been called once on the primary CPU, and we know that this will set the memory management context to the first task, set the program counter to it and execute it. This is the most brutal approach to having a process scheduled, and we will detail what happens further down.
We must however look at the bigger picture of kernel preemtion to get the full picture of what happens here.
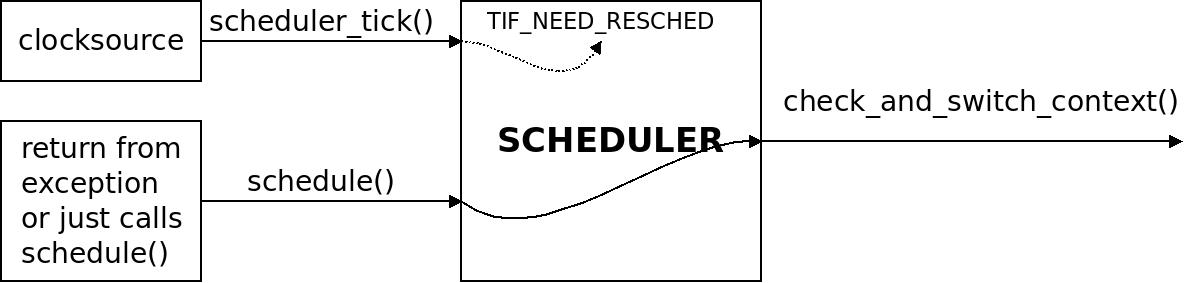 A mental model of the scheduler: scheduler_tick() sets the flag TIF_NEED_RESCHED and a later call to schedule() will actually call out to check_and_switch_context() that does the job of switching task.
A mental model of the scheduler: scheduler_tick() sets the flag TIF_NEED_RESCHED and a later call to schedule() will actually call out to check_and_switch_context() that does the job of switching task.
Scheduler tick and TIF_NEED_RESCHED
As part of booting the kernel in start_kernel() we first initialized the scheduler with a call to sched_init() and the system tick with a call to tick_init() and then the timer drivers using time_init(). The time_init() call will go through some loops and hoops and end up initializing and registering the clocksource driver(s) for the system, such as those that can be found in drivers/clocksource.
There will sometimes be only a broadcast timer to be used by all CPU:s on the system (the interrupts will need to be broadcast to all the CPU:s using IPC interrupts) and sometimes more elaborate architectures have timers dedicated to each CPU so these can be used invidually by each core to plan events and drive the system tick on that specific CPU.
The most suitable timer will also be started as part of the clockevent device(s) being registered. However, it's interrupt will not be able to fire until local_irq_enable() is called further down in start_kernel(). After this point the system has a running scheduling tick.
As scheduling happens separately on each CPU, scheduler timer interrupts and rescheduling calls needs to be done separately on each CPU as well.
The clockevent drivers can provide a periodic tick and then the process will be interrupted after an appropriate number of ticks, or the driver can provide oneshot interrupts, and then it can plan an event further on, avoiding to fire interrupts while the task is running just for ticking and switching itself (a shortcut known as NO_HZ).
What we know for sure is that this subsystem always has a new tick event planned for the system. It can happen in 1/HZ seconds if periodic ticks are used, or it can happen several minutes into the future if nothing happens for a while in the system.
When the clockevent eventually fires, in the form of an interrupt from the timer, it calls its own ->event_handler() which is set up by the clockevent subsystem code. When the interrupt happens it will fast-forward the system tick by repetitive calls to do_timer() followed by a call to scheduler_tick(). (We reach this point through different paths depending on whether HRTimers and other kernel features are enabled or not.)
As a result of calling scheduler_tick(), some scheduler policy code such as deadline, CFS, etc (this is explained by many others elsewhere) will decide that the current task needs to be preempted, “rescheduled” and calls resched_curr(rq) on the runqueue for the CPU, which in turn will call set_tsk_need_resched(curr) on the current task, which flags it as ready to be rescheduled.
set_tsk_need_resched() will set the flag TIF_NEED_RESCHED for the task. The flag is implemented as an arch-specific bitfield, in the ARM32 case in arch/arm/include/asm/thread_info.h and ARM32 has a bitmask version of this flag helpfully named _TIF_NEED_RESCHED that can be used by assembly snippets to check it quickly with a logical AND operation.
This bit having been set does not in any way mean that a new process will start executing immediately. The flag semantically means “at your earliest convenience, yield to another task”. So the kernel waits until it finds an appropriate time to preempt the task, and that time is when schedule() is called.
The Task State and Stack
We mentioned the architecture-specific struct thread_info so let's hash out where that is actually stored. It is a simpler story than it used to be, because these days, the the ARM32 thread_info is simply part of the task_struct. The struct task_struct is the central per-task information repository that the generic parts of the Linux kernel holds for a certain task, and paramount to keeping the task state. Here is a simplified view that gives you an idea about how much information and pointers it actually contains:
struct task_struct {
struct thread_info thread_info;
(...)
unsigned int state;
(...)
void *stack;
(...)
struct mm_struct *mm;
(...)
pid_t pid;
(...)
};
The struct thread_info which in our case is a member of task_struct contains all the architecture-specific aspects of the state.
The task_struct refers to thread_info, but also to a separate piece of memory void *stack called the task stack, which is where the task will store its activation records when executing code. The task stack is of size THREAD_SIZE, usually 8KB (2 * PAGE_SIZE). These days, in most systems, the task stack is mapped into the VMALLOC area.
The last paragraph deserves some special mentioning with regards to ARM32 because things changed. Ard Biesheuvel recently first enabled THREAD_INFO_IN_TASK which enabled thread info to be contained in the task_struct and then enabled CONFIG_VMAP_STACK for all systems in the ARM32 kernel. This means that the VMALLOC memory area is used to map and access the task stack. This is good for security reasons: the task stack is a common target for kernel security exploits, and by moving this to the VMALLOC area, which is simply a huge area of virtual memory addresses, and surrounding it below and above with unmapped pages, we will get a page violation if a the kernel tries to access memory outside the current task stack!
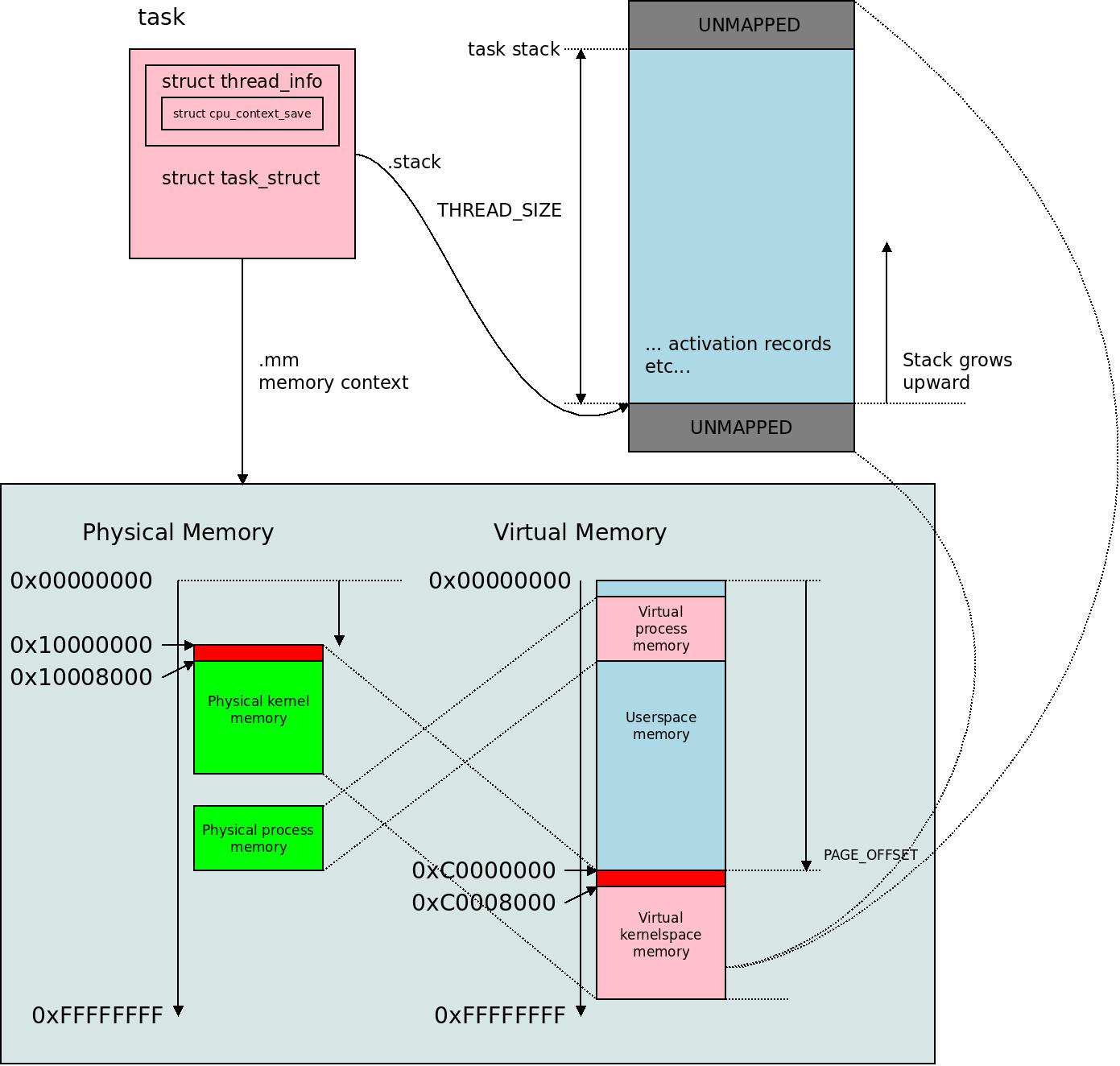 The task_struct in the Linux kernel is where the kernel keeps a nexus of all information about a certain task, i.e. a certain processing context. It contains .mm the memory context where all the virtual memory mappings live for the task. The thread_info is inside it, and inside the thread_info is a cpu_context_save. It has a task stack of size THREAD_SIZE for ARM32 which is typically twice the PAGE_SIZE, i.e. 8KB, surrounded by unmapped memory for protection. Again this memory is mapped in the memory context of the process. The split between task_struct and thread_info is such that task_struct is Linux-generic and thread_info is architecture-specific and they correspond 1-to-1.
The task_struct in the Linux kernel is where the kernel keeps a nexus of all information about a certain task, i.e. a certain processing context. It contains .mm the memory context where all the virtual memory mappings live for the task. The thread_info is inside it, and inside the thread_info is a cpu_context_save. It has a task stack of size THREAD_SIZE for ARM32 which is typically twice the PAGE_SIZE, i.e. 8KB, surrounded by unmapped memory for protection. Again this memory is mapped in the memory context of the process. The split between task_struct and thread_info is such that task_struct is Linux-generic and thread_info is architecture-specific and they correspond 1-to-1.
Actual Preemption
In my mind, preemption happens when the program counter is actually set to a code segment in a different process, and this will happen at different points depending on how the kernel is configured. This happens as a result of schedule() getting called, and will in essence be a call down to the architecture to switch memory management context and active task. But where and when does schedule() get called?
schedule() can be called for two reasons:
- Voluntary preemption: such as when a kernel thread want to give up it's time slice because it knows it cannot proceed for a while. This is the case for most instances of this call that you find in the kernel. The special case when we start the kernel and call schedule_preempt_disabled() the very first time, we voluntarily preempt the kernel execution of the init task with PID 0 to instead execute whatever is queued and prioritized in the scheduler, and that will be the kthreadd process. Other places can be found by git grep:ing for calls to cond_resched() or just an explicit call to schedule().
- Forced preemption: this happens when a task is simply scheduled out. This happens to kernelthreads and userspace processes alike. This happens when a process has used up its' timeslice, and schedule_tick() has set the TIF_NEED_RESCHED flag. And we described in the previous section how this flag gets set from the scheduler tick.
Places where forced preemption happens:
The short answer to the question “where does forced preemption happen?” is “at the end of exception handlers”. Here are the details.
The most classical place for preemption of userspace processes is on the return path of a system call. This happens from arch/arm/kernel/entry-common.S in the assembly snippets for ret_slow_syscall() and ret_fast_syscall(), where the ARM32 kernel makes an explicit call to do_work_pending() in arch/arm/kernel/signal.c. This will issue a call to schedule() if the flag _TIF_NEED_RESCHED is set for the thread, and the the kernel will handle over execution to whichever task is prioritized next, no matter whether it is a userspace or kernelspace task. A special case is ret_from_fork which means a new userspace process has been forked and in many cases the parent gets preempted immediately in favor of the new child through this path.
The most common place for preemption is however when returning from a hardware interrupt. Interrupts on ARM32 are handled in assembly in arch/arm/kernel/entry-armv.S with a piece of assembly that saves the processor state for the current CPU into a struct pt_regs and from there just calls the generic interrupt handling code in kernel/irq/handle.c named generic_handle_arch_irq(). This code is used by other archs than ARM32 and will nominally just store the system state and registers in a struct pt_regs record on entry and restore it on exit. However when the simplistic code in generic_handle_arch_irq() is done, it exits through the same routines in arch/arm/kernel/entry-common.S as fast and slow syscalls, and we can see that in ret_to_user_from_irq the code will explicitly check for the resched and other flags with ldr r1, [tsk, #TI_FLAGS] and branch to the handler doing do_work_pending(), and consequently preempt to another task instead of returning from an interrupt.
Now study do_work_pending():
do_work_pending(struct pt_regs *regs, unsigned int thread_flags, int syscall)
{
/*
* The assembly code enters us with IRQs off, (...)
*/
do {
if (likely(thread_flags & _TIF_NEED_RESCHED)) {
schedule();
} else {
(...)
}
local_irq_disable();
thread_flags = read_thread_flags();
} while (...);
return 0;
}
Notice the comment: we enter do_work_pending() with local IRQs disabled so we can't get interrupted in an interrupt (other exceptions can still happen though). Then we likely call schedule() and another thread needs to start to run. When we return after having scheduled another thread we are supposed proceed to exit the exception handler with interrupts disabled, so that is why the first instruction after the if/else-clause is local_irq_disable() – we might have come back from a kernel thread which was happily executing with interrupts enabled. So disable them. In fact, if you grep for do_work_pending you will see that this looks the same on other architectures with similar setup.
In reality do_work_pending() does a few more things than preemption: it also handles signals between processes and process termination etc. But for this exercise we only need to know that it calls schedule() followed by local_irq_disable().
The struct pt_regs should be understood as “processor trace registers” which is another historical naming, much due to its use in tracing. On ARM32 it is in reality 18 32-bit words representing all the registers and status bits of the CPU for a certain task, i.e. the CPU state, including the program counter pc, which is the place where the task was supposed to resume execution, unless it got preempted by schedule(). This way, if we preempt and leave a task behind, the CPU state contains all we need to know to continue where we left off. These pt_regs are stored in the task stack during the call to generic_handle_arch_irq().
The assembly in entry-common.S can be a bit hard to follow, here is a the core essentials for a return path from an interrupt that occurs while we are executing in userspace:
(...)
slow_work_pending:
mov r0, sp @ 'regs'
mov r2, why @ 'syscall'
bl do_work_pending
cmp r0, #0
beq no_work_pending
(...)
ENTRY(ret_to_user_from_irq)
ldr r1, [tsk, #TI_FLAGS]
movs r1, r1, lsl #16
bne slow_work_pending
no_work_pending:
asm_trace_hardirqs_on save = 0
ct_user_enter save = 0
restore_user_regs fast = 0, offset = 0
We see that when we return from an IRQ, we check the flags in the thread and if any bit is set we branch to execute slow work, which is done by do_work_pending() which will potentially call schedule(), then return, possibly much later, and if all went fine branch back to no_work_pending and restore the usersmode registers and continue execution.
Notice that the exception we are returning from here can be the timer interrupt that was handled by the Linux clockevent and driving the scheduling by calling scheduler_tick()! This means we can preempt directly on the return path of the interrupt that was triggered by the timer tick. This way the slicing of task time is as precise as it can get: scheduler_tick() gets called by the timer interrupt, and if it sets TIF_NEED_RESCHED a different thread will start to execute on our way out of the exception handler!
The same path will be taken by SVC/SWI software exceptions, so these will also lead to rescheduling of necessary. The routine named restore_user_regs can be found in entry-header.S and it will pretty much do what it says, ending with the following instructions (if we remove quirks and assume slowpath):
mov r2, sp
(...)
ldmdb r2, {r0 - lr}^ @ get calling r0 - lr
add sp, sp, #\offset + PT_REGS_SIZE
movs pc, lr @ return & move spsr_svc into cp
r2 is set to the stack pointer, where pt_regs are stored, these are 17 registers and CPSR (current program status register). We pull the registers from the stack (including r2 which gets overwritten) — NOTE: the little caret (^) after the ldmdb instruction means “also load CPSR from the stack” — then moves the stackpointer past the saved registers and returns.
Using the exceptions as a point for preemption is natural: exceptions by their very nature are designed to store the processor state before jumping to the exception handler, and it is strictly defined how to store this state into memory such as onto the per-task task stack, and how to reliably restore it at the end of an exception. So this is a good point to do something else, such as switch to something completely different.
Also notice that this must happen in the end of the interrupt (exception) handler. You can probably imagine what would happen on a system with level-triggered interrupts if we would say preempt in the beginning of the interrupt instead of the end: we would not reach the hardware interrupt handler, and the interrupt would not be cleared. Instead, we handle the exception, and then when we are done we optionally check if preemption should happen right before returning to the interrupted task.
But let's not skip the last part of what schedule() does.
Setting the Program Counter
So we now know a few places where the system can preempt and on ARM32 we see that this mostly happens in the function named do_work_pending() which in turn will call schedule() for us.
The schedulers schedule() call is supposed to very quickly select a process to run next. Eventually it will call context_switch() in kernel/sched/core.c, which in turn will do essentially two things:
- Check if the next task has a unique memory management context (
next->mmis not NULL) and in that case switch the memory management context to the next task. This means updating the MMU to use a different MMU table. Kernel threads do not have any unique memory management context so for those we can just keep the previous context (the kernel virtual memory is mapped into all processes on ARM32 so we can just go on). If the memory management context does switch, we call switch_mm_irqs_off() which in the ARM32 case is just defined to the ARM32-specific switch_mm() which will call the ARM32-specific check_and_switch_context() — NOTE that this function for any system with MMU is hidden in thearch/arm/include/asm/mmu_context.hheader file — which in turn does one of two things:- If interrupts are disabled, we will just set
mm->context.switch_pending = 1so that the memory management context switch will happen at a later time when we are running with interrupts enabled, because it will be very costly to switch task memory context on ARM32 if interrupts are disabled on certain VIVT (virtually indexed, virtually tagged) cache types, and this in turn would cause unpredictable IRQ latencies on these systems. This concerns some ARMv6 cores. The reason why interrupts would be disabled in a schedule() call is that it will be holding a runqueue lock, which in turn disables interrupts. Just like the comment in the code says, this will be done later in the arch-specific finish_arch_post_lock_switch() which is implemented right below and gets called right after dropping the runqueue lock. - If interrupts are not disabled, we will immediately call cpu_switch_mm(). This is a per-cpu callback witch is written in assembly for each CPU as cpu_NNNN_switch_mm() inside
arch/arm/mm/proc-NNNN.S. For example, all v7 CPUs have the cpu_v7_switch_mm() inarch/arm/mm/proc-v7.S.
- If interrupts are disabled, we will just set
- Switch context (such as the register states and stack) to the new task by calling switch_to() with the new task and the previous one as parameter. In most cases this latches to an architecture-specific __switch_to(). In the ARM32 case, this routine is written in assembly and can be found in
arch/arm/kernel/entry-armv.S.
Now the final details happens in __switch_to() which is supplied the struct thread_info (i.e. the architecture-specific state) for both the current and the previous task:
- We store the registers of the current task in the task stack, at the TI_CPU_SAVE index of
struct thread_info, which corresponds to the.cpu_contextentry in the struct, which is in turn astruct cpu_context_save, which is 12 32-bit values to store r4-r9, sl, fp, sp and pc. This is everything needed to continue as if nothing has happened when we “return” after the schedule() call. I put “return” in quotation marks, because a plethora of other tasks may have run before we actually get back there. You may ask why r0, r1, r2 and r3 are not stored. This will be addressed shortly. - Then the TLS (Thread Local Storage) settings for the new task are obtained and we issue switch_tls(). On v6 CPUs this has special implications, but in most cases we end up using switch_tls_software() which sets TLS to 0xffff0ff0 for the task. This is a hard-coded value in virtual memory used by the kernel-provided user helpers, which in turn are a few kernel routines “similar to but different from VDSO” that are utilized by the userspace C library. On ARMv7 CPUs that support the thread ID register (TPIDRURO) this will be used to store the
struct thread_infopointer, so it cannot be used for TLS on ARMv7. (More on this later.) - We then broadcast THREAD_NOTIFY_SWITCH using kernel notifiers. These are usually written i C but called from the assembly snippet __switch_to() here. A notable use case is that if the task is making use of VFP (the Vectored Floating Point unit) then the state of the VFP gets saved here, so that will be cleanly restored when the task resumes as well.
Then we reach the final step in __switch_to(), which is a bit different depending on whether we use CONFIG_VMAP_STACK or not.
The simple path when we are not using VMAP:ed stacks looks like this:
set_current r7, r8
ldmia r4, {r4 - sl, fp, sp, pc} @ Load all regs saved previously
Here r7 contains a pointer to the next tasks thread_info (which will somewhere the kernel virtual memory map), and set_current() will store the pointer to that task in such a way that the CPU can look it up with a few instructions at any point in time. On older non-SMP ARMv4 and ARMv5 CPU:s this will simply be the memory location pointed out by the label __current but ARMv7 and SMP systems have a dedicated special CP15 TPIDRURO thread ID register to store this in the CPU so that the thread_info can be located very quickly. (The only user of this information is, no surprise, the get_current() assembly snippet, but that is in turn called from a lot of places and contexts.)
The next ldmia instruction does the real trick: it loads registers r4 thru sl (r10), fp (r11), sp(r13) and pc(r15) from the location pointed out by r4, which again is the .cpu_context entry in the struct thread_info, the struct cpu_context_save, which is all the context there is including pc so the next instruction after this will be whatever pc was inside the struct cpu_context_save. We have switched to the new task and preemption is complete.
But wait a minute. r4 and up you say. Exept some registers, so what about r0, r1, r2, r3, r12 (ip) and r14 (lr)? Isn't the task we're switching to going to miss those registers?
For r0-r3 the short answer is that when we call schedule() explicitly (which only happens inside the kernel) then r0 thru r3 are scratch registers that are free to be “clobbered” during any function call. So since we call schedule() the caller should be prepared that those registers are clobbered anyway. The same goes for the status register CPSR. It's a function call to inline assembly and not an exception.
And even if we look around the context after a call to schedule(), since we were either (A) starting a brand new task or (B) on our way out of an exception handler for a software or hardware interrupt or (C) explicitly called schedule() when this happened, this just doesn't matter.
Then r12 is a scratch register and we are not calling down the stack using lr at this point either (we just jump to pc!) so these two do not need to be saved or restored. (On the ARM or VMAP exit path you will find ip and lr being used.)
When starting a completely new task all the contents of struct cpu_context_save will be zero, and the return address will be set to ret_from_fork or and then the new task will bootstrap itself in userspace or as a kernel thread anyway.
If we're on the exit path of an exception handler, we call various C functions and r0 thru r3 are used as scratch registers, meaning that their content doesn't matter. At the end of the exception (which we are close to when we call schedule()) all registers and the CPSR will be restored from the kernel exception stacks record for pt_regs before the exception returns anyway, which is another good reason to use exceptions handlers as preemption points.
This is why r0 thru r3 are missing from struct cpu_context_save and need not be preserved.
When the scheduler later on decides to schedule in the task that was interrupted again, we will return to execution right after the schedule(); call. If we were on our way out of an exception in do_work_pending() we will proceed to return from the exception handler, and to the process it will “feel” like it just returned from a hardware or sofware interrupt, and execution will go on from that point like nothing happened.
Running init
So how does /sbin/init actually come to execute?
We saw that after start_kernel we get to rest_init which creates the thread with pid = user_mode_thread(kernel_init, NULL, CLONE_FS).
Then kernel_init calls on kernel_execve() to execute /sbin/init. It locates an ELF parser to read and page in the file. Then it will eventually issue start_thread() which will set regs->ARM_cpsr = USR_MODE and regs->ARM_pc to the start of the executable.
Then this tasks task_struct including memory context etc will be selected after a call to schedule().
But every call to schedule() will return to the point right after a schedule() call, and the only place a userspace task is ever preempted to get schedule() called on it is in the exception handlers, such as when a timer interrupt occurs. Well, this is where we “cheat”:
When we initialized the process in arch/arm/kernel/process.c, we set the program counter to ret_from_fork so we are not going back after any schedule() call: we are going back to ret_from_fork! And this is just an exception return path, so this will restore regs->ARM_cpsr to USR_MODE, and “return from an exception” into whatever is in regs->ARM_pc, which is the start of the binary program from the ELF file!
So /sbin/init is executed as a consequence of returning from a fake exception through ret_from_fork. From that point on, only real exceptions, such as getting interrupted by the IRQ, will happen to the process.
This is how ARM32 schedules and executes processes.