How the ARM32 kernel starts
My previous article on how the kernel decompresses generated a lot of traffic and commentary, much to my surprise. I suppose that this may be because musings of this kind fill the same niche as the original Lions' Commentary on UNIX 6th Edition, with Source Code which was a major hit in the late 1970s. Operating system developers simply like to read expanded code comments, which is what this is.
When I’m talking about “ARM32” the proper ARM name for this is Aarch32 and what is implemented physically in the ARMv4 thru ARMv7 ARM architectures.
In this post I will discuss how the kernel bootstraps itself from executing in physical memory after decompression/boot loader and all the way to executing generic kernel code written in C from virtual memory.
This Is Where It All Begins
After decompression and after augmenting and passing the device tree blob (DTB) the ARM32 kernel is invoked by putting the program counter pc at the physical address of the symbol stext(), start of text segment. This code can be found in arch/arm/kernel/head.S.
A macro __HEAD places the code here in a linker section called .head.text and if you inspect the linker file for the ARM architecture at arch/arm/kernel/vmlinux.lds.S you will see that this means that the object code in this section will be, well, first.
This will be at a physical address which is evenly divisible by 16MB and an additional 32KB TEXT_OFFSET (which will be explained more later) so you will find stext() at an address such as 0x10008000, which is the address we will use in our example.
head.S contains a small forest of exceptions for different old ARM platforms making it hard to tell the trees from the forest. The standards for ATAGs and device tree boots came about since it was written so this special code has become increasingly complex over the years.
To understand the following you need a basic understanding of paged virtual memory. If Wikipedia is too terse, refer to Hennesy & Patterson’s book “Computer Architecture: A Quantitative Approach”. Knowing a bit of ARM assembly language and Linux kernel basics is implied.
ARM’s Virtual Memory Split
Let’s first figure out where in virtual memory the kernel will actually execute. The kernel RAM base is defined in the PAGE_OFFSET symbol, which is something you can configure. The name PAGE_OFFSET shall be understood as the virtual memory offset for the first page of kernel RAM.
You choose 1 out of 4 memory split alternatives, which reminds me about fast food restaurants. It is currently defined like this in arch/arm/Kconfig:
config PAGE_OFFSET
hex
default PHYS_OFFSET if !MMU
default 0x40000000 if VMSPLIT_1G
default 0x80000000 if VMSPLIT_2G
default 0xB0000000 if VMSPLIT_3G_OPT
default 0xC0000000
First notice that if we don’t have an MMU (such as when running on ARM Cortex-R class devices or old ARM7 silicon) we will create a 1:1 mapping between physical and virtual memory. The page table will then only be used to populate the cache and addresses are not rewritten. PAGE_OFFSET could very typically be at address 0x00000000 for such set-ups. Using the Linux kernel without virtual memory is referred to as “uClinux” and was for some years a fork of the Linux kernel before being brought in as part of the mainline kernel.
Not using virtual memory is considered an oddity when using Linux or indeed any POSIX-type system. Let us from here on assume a boot using virtual memory.
The PAGE_OFFSET virtual memory split symbol creates a virtual memory space at the addresses above it, for the kernel to live in. So the kernel keep all its code, state and data structures (including the virtual-to-physical memory translation table) at one of these locations in virtual memory:
- 0x40000000-0xFFFFFFFF
- 0x80000000-0xFFFFFFFF
- 0xB0000000-0xFFFFFFFF
- 0xC0000000-0xFFFFFFFF
Of these four, the last location at 0xC0000000-0xFFFFFFFF is by far the most common. So the kernel has 1GB of address space to live in.
The memory below the kernel, from 0x00000000-PAGE_OFFSET-1, i.e. typically at address 0x00000000-0xBFFFFFFF (3 GB) is used for userspace code. This is combined with the Unix habit to overcommit, which means that you optimistically offer programs more virtual memory space than what you have physical memory available for. Every time a new userspace process starts up it thinks that it has 3 gigabytes of memory to use! This type of overcommit has been a characteristic of Unix systems since their inception in the 1970s.
Why are there four different splits?
This is pretty straightforward to answer: ARM is heavily used for embedded systems and these can be either userspace-heavy (such as an ordinary tablet or phone, or even a desktop computer) or kernel-heavy (such as a router). Most systems are userspace-heavy or have so little memory that the split doesn’t really matter (neither will be very occupied), so the most common split is to use PAGE_OFFSET 0xC0000000.
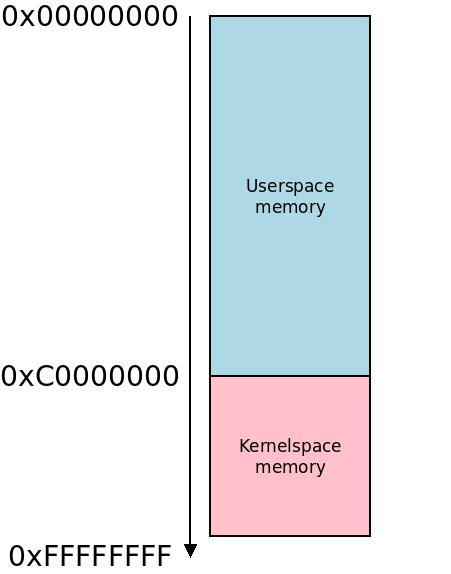 The most common virtual memory split between kernelspace and userspace memory is at
The most common virtual memory split between kernelspace and userspace memory is at 0xC0000000. A notice on these illustrations: when I say memory is “above” something I mean lower in the picture, along the arrow, toward higher addresses. I know that some people perceive this as illogical and turn the figure upside-down with 0xFFFFFFFF on the top, but it is my personal preference and also the convention used in most hardware manuals.
It could happen that you have a lot of memory and a kernel-heavy use case, such as a router or NAS with lots of memory, say a full 4GB of RAM. You would then like the kernel to be able to use some of that memory for page cache and network cache to speed up your most typical use case, so you will select a split that gives you more kernel memory, such as in the extreme case PAGE_OFFSET 0x40000000.
This virtual memory map is always there, also when the kernel is executing userspace code. The idea is that by keeping the kernel constantly mapped in, context switches from userspace to kernelspace become really quick: when a userspace process want to ask the kernel for something, you do not need to replace any page tables. You just issue a software trap to switch to supervisor mode and execute kernel code, and the virtual memory set-up stays the same.
Context switches between different userspace processes also becomes quicker: you will only need to replace the lower part of the page table, and typically the kernel mapping as it is simple, uses a predetermined chunk of physical RAM (the physical RAM where it was loaded to begin with) and is linearly mapped, is even stored in a special place, the translation lookaside buffer. The translation lookaside buffer, “special fast translation tables in silicon”, makes it even faster to get into kernelspace. These addresses are always present, always linearly mapped, and will never generate a page fault.
Where Are We Executing?
We continue looking at arch/arm/kernel/head.S, symbol stext().
The next step is to deal with the fact that we are running in some unknown memory location. The kernel can be loaded anywhere (provided it is a reasonably even address) and just executed, so now we need to deal with that. Since the kernel code is not position-independent, it has been linked to execute at a certain address by the linker right after compilation. We don’t know that address yet.
The kernel first checks for some special features like virtualization extensions and LPAE (large physical address extension) then does this little dance:
adr r3, 2f
ldmia r3, {r4, r8}
sub r4, r3, r4 @ (PHYS_OFFSET - PAGE_OFFSET)
add r8, r8, r4 @ PHYS_OFFSET
(...)
2: .long .
.long PAGE_OFFSET
.long . is link-time assigned to the address of the label 2: itself, so . is resolved to the address that the label 2: is actually linked to, where the linker imagines that it will be located in memory. This location will be in the virtual memory assigned to the kernel, i.e. typically somewhere above 0xC0000000.
After that is the compiled-in constant PAGE_OFFSET, and we already know that this will be something like 0xC0000000.
We load in the compile-time address if 2: into r4 and the constant PAGE_OFFSET into r8. Then we subtract that from the actual address of 2:, which we have obtained in r3 using relative instructions, from r4. Remember that ARM assembly argument order is like a pocket calculator: sub ra, rb, rc => ra = rb - rc.
The result is that we have obtained in r4 the offset between the address the kernel was compiled to run at, and the address it is actually running at. So the comment @ (PHYS_OFFSET - PAGE_OFFSET) means we have this offset. If the kernel symbol 2: was compiled to execute at 0xC0001234 in virtual memory but we are now executing at 0x10001234 r4 will contain 0x10001234 - 0xC0001234 = 0x50000000. This can be understood as “-0xB0000000” because the arithmetic is commutative: 0xC0001234 + 0x50000000 = 0x10001234, QED.
Next we add this offset to the compile-time assigned PAGE_OFFSET that we know will be something like 0xC0000000. With wrap-around arithmetic, if we are again executing at 0x10000000 we get 0xC0000000 + 0x50000000 = 0x10000000 and we obtained the base physical address where the kernel is currently actually executing in r8 – hence the comment @PHYS_OFFSET. This value in r8 is what we are actually going to use.
The elder ARM kernel had a symbol called PLAT_PHYS_OFFSET that contained exactly this offset (such as 0x10000000), albeit compile-time assigned. We don’t do that anymore: we assign this dynamically as we shall see. If you are working with operating systems less sophisticated than Linux you will find that the developers usually just assume something like this in order to make things simple: the physical offset is a constant. Linux has evolved to this because we need to handle booting of one single kernel image on all kinds of memory layouts.
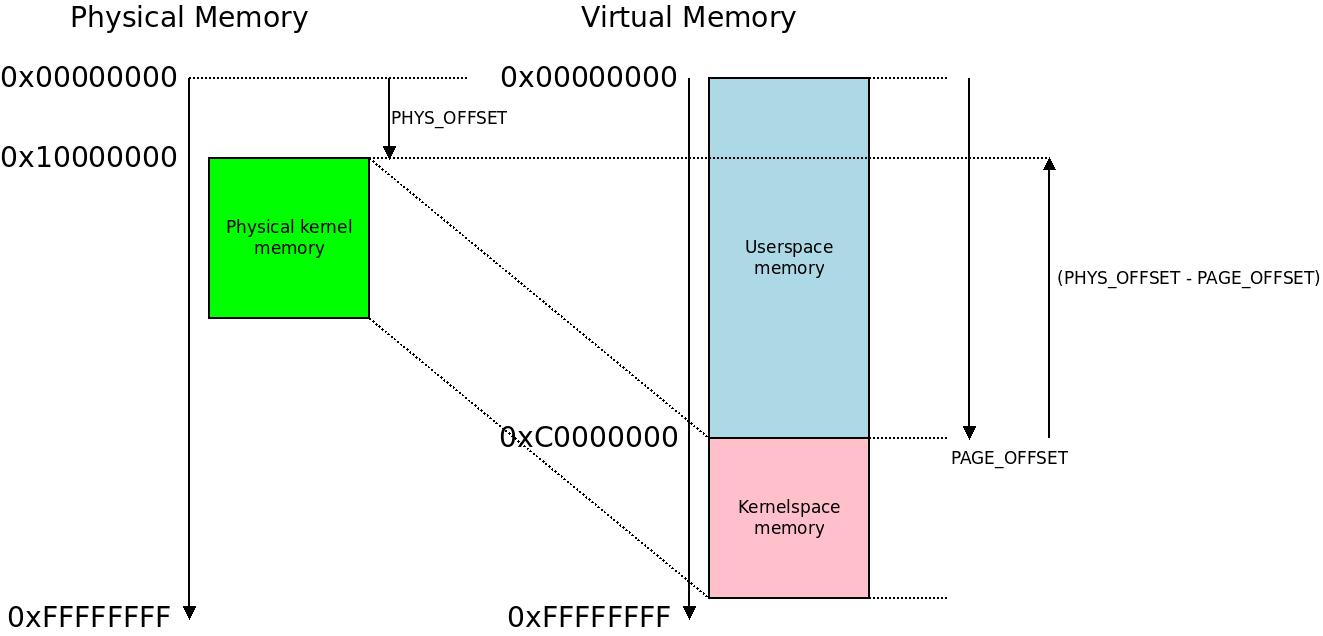 I do not know if this picture makes things easier or harder to understand. It illustrates physical to virtual memory mapping in our example.
I do not know if this picture makes things easier or harder to understand. It illustrates physical to virtual memory mapping in our example.
There are some rules around PHYS_OFFSET: it needs to adhere to some basic alignment requirements. When we determine the location of the first block of physical memory in the uncompress code we do so by performing PHYS = pc & 0xF8000000, which means that the physical RAM must start at an even 128 MB boundary. If it starts at 0x00000000 that’s great for example.
There are some special considerations around this code for the XIP “execute in place” case when the kernel is executing from ROM (read only memory) but we leave that aside, it is another oddity, even less common than not using virtual memory.
Notice one more thing: you might have attempted to load an uncompressed kernel and boot it and noticed that the kernel is especially picky about where you place it: you better load it to a physical address like 0x00008000 or 0x10008000 (assuming that your TEXT_OFFSET is 0x8000). If you use a compressed kernel you get away from this problem because the decompressor will decompress the kernel to a suitable location (very often 0x00008000) and solve this problem for you. This is another reason why people might feel that compressed kernels “just work” and is kind of the norm.
Patching Physical to Virtual (P2V)
Now that we have the offset between virtual memory where we will be executing and the physical memory where we are actually executing, we reach the first sign of the Kconfig symbol CONFIG_ARM_PATCH_PHYS_VIRT.
This symbol was created because developers were creating kernels that needed to boot on systems with different memory configurations without recompiling the kernel. The kernel would be compiled to execute at a certain virtual address, like 0xC0000000, but can be loaded into memory at 0x10000000 like in our case, or maybe at 0x40000000, or some other address.
Most of the symbols in the kernel will not need to care of course: they are executed in virtual memory at an adress to which they were linked and to them we are always running at 0xC0000000. But now we are not writing some userspace program: things are not easy. We have to know about the physical memory where we are executing, because we are the kernel, which means that among other things we need to set up the physical-to-virtual mapping in the page tables, and regularly update these page tables.
Also, since we don’t know where in the physical memory we will be running, we cannot rely on any cheap tricks like compile-time constants, that is cheating and will create hard to maintain code full of magic numbers.
For converting between physical and virtual addresses the kernel has two functions: __virt_to_phys() and __phys_to_virt() converting kernel addresses in each direction (not any other addresses than those used by the kernel memory). This conversion is linear in the memory space (uses an offset in each direction) so it should be possible to achieve this with a simple addition or subtraction. And this is what we set out to do, and we give it the name “P2V runtime patching” . This scheme was invented by Nicolas Pitre, Eric Miao and Russell King in 2011 and in 2013 Santosh Shilimkar extended the scheme to also apply to LPAE systems, specifically the TI Keystone SoC.
The main observation is that if it holds that, for a kernel physical address PHY and a kernel virtual address VIRT (you can convince yourself of these two by looking at the last illustration):
PHY = VIRT – PAGE_OFFSET + PHYS_OFFSET VIRT = PHY – PHYS_OFFSET + PAGE_OFFSET
Then by pure laws of arithmetics it also holds that:
PHY = VIRT + (PHYS_OFFSET – PAGE_OFFSET) VIRT = PHY – (PHYS_OFFSET – PAGE_OFFSET)
So it is possible to always calculate the physical address from a virtual address by an addition of a constant and to calculate the virtual address from a physical address by a subtraction, QED. That is why the initial stubs looked like this:
static inline unsigned long __virt_to_phys(unsigned long x)
{
unsigned long t;
__pv_stub(x, t, "add");
return t;
}
static inline unsigned long __phys_to_virt(unsigned long x)
{
unsigned long t;
__pv_stub(x, t, "sub");
return t;
}
The __pv_stub() would contain an assembly macro to do add or sub. Since then the LPAE support for more than 32-bit addresses made this code a great deal more complex, but the general idea is the same.
Whenever __virt_to_phys() or __phys_to_virt() is called in the kernel, it is replaced with a piece of inline assembly code from arch/arm/include/asm/memory.h, then the linker switches section to a section called .pv_table, and then adds a entry to that section with a pointer back to the assembly instruction it just added. This means that the section .pv_table will expand into a table of pointers to any instance of these assembly inlines.
During boot, we will go through this table, take each pointer, inspect each instruction it points to, patch it using the offset to the physical and virtual memory where we were actually loaded.
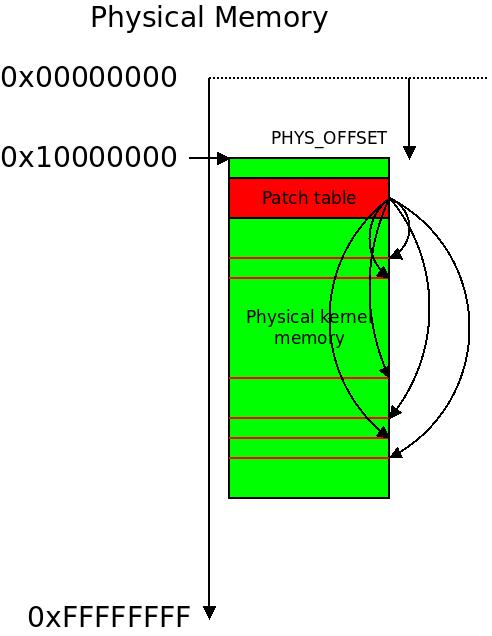 Each and every location with an assembly macro doing a translation from physical to virtual memory is patched in the early boot process.
Each and every location with an assembly macro doing a translation from physical to virtual memory is patched in the early boot process.
Why are we doing this complex manouver instead of just storing the offset in a variable? This is for efficiency reasons: it is on the hot data path of the kernel. Calls updating page tables and cross-referencing physical to virtual kernel memory are extremely performance-critical, all use cases exercising the kernel virtual memory, whether block layer or network layer operations, or user-to-kernelspace translations, in principle any data passing through the kernel, will at some point call these functions. They must be fast.
It would be wrong to call this a simple solution to the problem. Alas it is a really complicated solution to the problem. But it works and it is very efficient!
Looping through the patch table
We perform the actual patching by figuring out the offset like illustrated above, and iteratively patching all the assembly stubs. This is done in the call to the symbol __fixup_pv_table, where our just calculated offset in r8 comes into play: a table of 5 symbols that need to refer directly to physical memory known as the __pv_table is read into registers r3..r7 augmented using the same method described above (that is why the table is preceded by a .long .):
__fixup_pv_table:
adr r0, 1f
ldmia r0, {r3-r7}
mvn ip, #0
subs r3, r0, r3 @ PHYS_OFFSET - PAGE_OFFSET
add r4, r4, r3 @ adjust table start address
add r5, r5, r3 @ adjust table end address
add r6, r6, r3 @ adjust __pv_phys_pfn_offset address
add r7, r7, r3 @ adjust __pv_offset address
mov r0, r8, lsr #PAGE_SHIFT @ convert to PFN
str r0, [r6] @ save computed PHYS_OFFSET to __pv_phys_pfn_offset
(...)
b __fixup_a_pv_table
1: .long .
.long __pv_table_begin
.long __pv_table_end
2: .long __pv_phys_pfn_offset
.long __pv_offset
The code uses the first value loaded into r3 to calculate the offset to physical memory, then adds that to each of the other registers so that r4 thru r7 now point directly to the physical memory contained in each of these labels. So r4 is a pointer to the physical memory storing __pv_table_begin, r5 points to __pv_table_end, r6 point to __pv_phys_pfn_offset and r7 points to __pv_offset. In C these would be u32 *, so pointers to some 32 bit numbers.
__pv_phys_pfn_offset is especially important, this means patch physical to virtual page frame number offset, so we first calculate this by making a logical shift right with mov r0, r8, lsr #PAGE_SHIFT using the value we earlier calculated in r8 (the offset from 0 to the kernel memory in our case 0x10000000), and writing it right into whatever location actually stores that variable with str r0, [r6]. This isn't used at this early stage of the kernel start-up but it will be used by the virtual memory manager later.
Next we call __fixup_a_pv_table which will loop over the addresses from r4 thru r5 (the table of pointers to instructions to be patched) and patch each of them in order using a custom binary patcher that convert the instructions whether in ARM or THUMB2 (the instruction set is known at compile time) to one with an immediate offset between physical and virtual memory encoded right into it. The code is pretty complex and contains quirks to accommodate for big endian byte order as well.
Notice that this also has to happen every time the kernel loads a module, who knows if the new module needs to convert between physical and virtual addresses! For this reason all module ELF files will contain a .pv_table section with the same kind of table and the very same assembly loop is called also every time we load a module.
Setting Up the Initial Page Table
Before we can start to execute in this virtual memory we have just chiseled out, we need to set up a MMU translation table for mapping the physical memory to virtual memory. This is commonly known as a page table, albeit what will use for the initial map is not pages but sections. The ARM architecture mandates that this must be placed on an even 16KB boundary in physical memory. Since it is also always 16KB in size this makes sense.
The location of the initial page table is defined in a symbol named swapper_pg_dir, “swapper page directory”, which is an idiomatic name for the initial page table for the kernel. As you realize it will later on be replaced (swapped, hence “swapper”) by a more elaborate page table.
The name “page table” is a bit misleading because what the initial mapping is using in ARM terminology is actually called sections, not pages. But the term is used a bit fuzzily to refer to “that thing which translates physical addresses to virtual addresses at boot”.
The symbol swapper_pg_dir is defined to be at KERNEL_RAM_VADDR - PG_DIR_SIZE. Let’s examine each of these.
KERNEL_RAM_VADDR is just what you would suspect: the address in the virtual memory where the kernel is located. It is the address to which the kernel was linked during compile.
The KERNEL_RAM_VADDR is defined to (PAGE_OFFSET + TEXT_OFFSET). PAGE_OFFSET can be one of four locations from the Kconfig symbol we just investigated, typically 0xC0000000. The TEXT_OFFSET is typically 0x8000, so the KERNEL_RAM_VADDR will typically be 0xC0008000 but with a different virtual memory split setting or exotic TEXT_OFFSET it will be something different. TEXT_OFFSET comes from textof-y in arch/arm/Makefile and is usually 0x8000, but can also be 0x00208000 on some Qualcomm platforms and 0x00108000 again on some Broadcom platforms, making KERNEL_RAM_VADDR 0xC0208000 or similar.
What we know for sure is that this address was passed to the linker when linking the kernel: if you inspect the linker file for the ARM architecture at arch/arm/kernel/vmlinux.lds.S like we did in the beginning of the article you can see that the linker is indeed instructed to place this at . = PAGE_OFFSET + TEXT_OFFSET. The kernel has been compiled to execute at the address given in KERNEL_RAM_VADDR, even if the very earliest code, that we are analyzing right now, has been written in assembly to be position-independent.
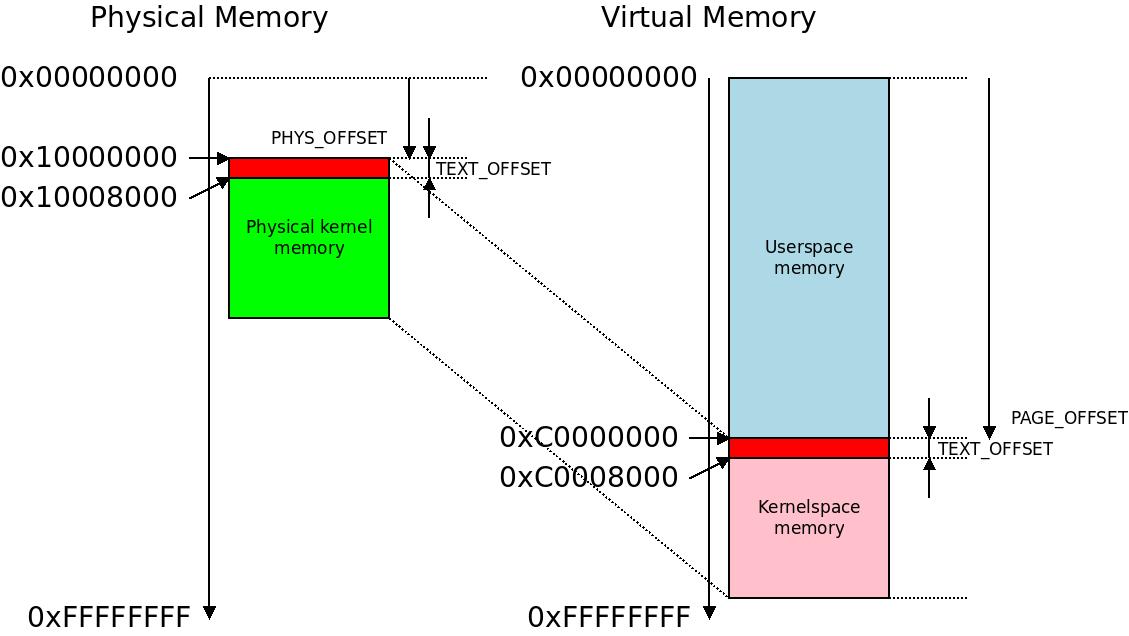 The
The TEXT_OFFSET is a small, typically 32KB area above the kernel RAM in both physical and virtual memory space. The location of the kernel in the physical RAM at 0x10000000 is just an example, this can be on any even 16MB boundary.
Notice that the little gap above the kernel, most commonly at 0xC0000000-0xC0007FFF (the typical 32KB if TEXT_OFFSET). While part of the kernelspace memory this is not memory that the kernel was compiled into: it contains the initial page table, potentially ATAGs from the boot loader and some scratch area and could be used for interrupt vectors if the kernel is located at 0x00000000. The initial page table here is certainly programmed and used by the kernel, but it is abandoned afterwards.
Notice that we add the same TEXT_OFFSET to physical and virtual memory alike. This is even done in the decompression code, which will decompress the kernel first byte of the kernel to PHYS_OFFSET + TEXT_OFFSET, so the linear delta between a kernel location in physical memory and the same location in virtual memory is always expressed in a few high bits of a 32bit word, such as bits 24 thru 31 (8 bits) making it possible to use immediate arithmetic and include the offset directly in the instruction we use when facilitating ARM_PATCH_PHYS_VIRT. From this comes the restriction that kernel RAM must begin at an address evenly divisible by 16MB (0x01000000).
So we find the physical location of swapper_pg_dir in virtual memory by adding TEXT_OFFSET to PAGE_OFFSET and then backing off PG_DIR_SIZE from there. In the common case this will be 0xC0000000 + 0x8000 - 0x4000 so the initial page table will be at 0xC0004000 in virtual memory and at the corresponding offset in physical memory, in my example with PHYS_OFFSET being 0x10000000 it will be at 0x10004000.
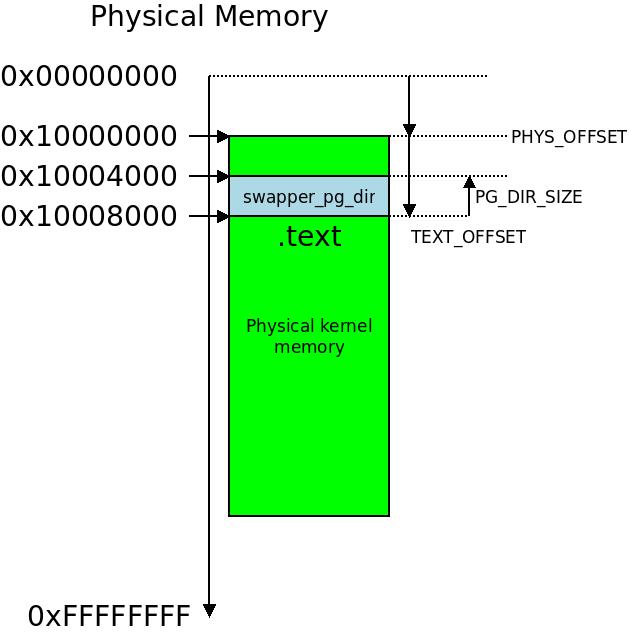 The swapper_pg_dir symbol will in our example reside 16KB (
The swapper_pg_dir symbol will in our example reside 16KB (0x4000 bytes) before the .text segment in physical memory, at 0x10004000 given that our PHYS_OFFSET is 0x10000000 and TEXT_OFFSET is 0x8000 while using classic ARM MMU.
If you use LPAE the page table PG_DIR_SIZE is 0x5000 so we end up at 0xC0003000 virtual and 0x10003000 physical. The assembly macro pgtbl calculates this for us: we take the physical address we have calculated in r8, add TEXT_OFFSET and subtract PG_DIR_SIZE and we end up on the physical address for the initial translation table.
The initial page table is constructed in a very simple way: we first fill the page table with zeroes, then build the initial page table. This happens at symbol __create_page_tables.
The ARM32 Page Table Format
The page table layout on ARM32 consists of 2 or 3 levels. The 2-level page table is referred to as the short format page table and the 3-level format is called the long format page table in ARM documentation. The long format is a feature of the large physical address extension, LPAE and as the name says it is there to handle larger physical memories requiring up to 40 bits of physical address.
These translation tables can translate memory in sections of 1MB (this is 2MB on LPAE but let’s leave that aside for now) or in pages of 16kB. The initial page table uses sections, so memory translation in the initial page table is exclusively done in sections of 1MB.
This simplifies things for the initial mapping: sections can be encoded directly in the first level of the page table. This way there is in general no need to deal with the complex 2-level hierarchy, and we are essentially treating the machine as something with 1-level 1MB section tables.
However if we are running on LPAE there is another level inbetween, so we need to deal with the first two levels and not just one level. That is why you find some elaborate LPAE code here. All it does is insert a 64bit pointer to our crude 2MB-sections translation table.
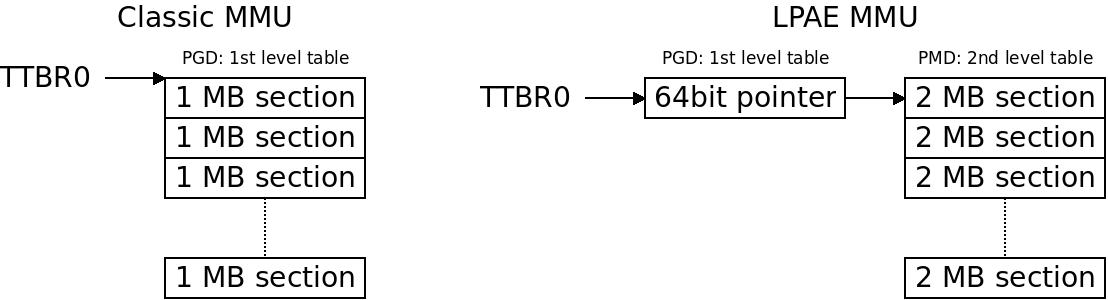 In the classic MMU we just point the MMU to a 1st level table with 1MB sections while for LPAE we need an intermediate level to get to the similar format with 2MB. The entries are called section descriptors.
In the classic MMU we just point the MMU to a 1st level table with 1MB sections while for LPAE we need an intermediate level to get to the similar format with 2MB. The entries are called section descriptors.
Linux Page Table Lingo
At this point the code starts to contain some three-letter acronyms. It is dubious whether these are actually meaningful when talking about this crude initial page table, but developers refer to these short-hands out of habit.
- PGD page global directory is Linux lingo for the uppermost translation table, where the whole MMU traversal to resolve sections and pages start. In our case this is at
0x10004000in physical memory. In the ARM32 world, this is also the address that we write into the specialCP15translation table register (sometimes calledTTBR0) to tell the MMU where to find the translations. If we were using LPAE this would be at0x10003000just to make space for that0x1000with a single 64bit pointer to the next level called PMD. - P4D page 4th level directory and PUD page upper directory are concepts in the Linux VMM (virtual memory manager) unused on ARM as these deal with translation table hierarchies of 4 or 5 levels and we use only 2 or 3.
- PMD page middle directory is the the name for 3rd level translation stage only used in LPAE. This is the reason we need to reserve another
0x1000bytes for the LPAE initial page table. For classic ARM MMU (non-LPAE) the PMD and the PGD is the same thing. This is why the code refers toPMD_ORDERfor classic MMU and LPAE alike. Because of Linux VMM terminology this is understood as the “format of the table right above the PTE:s”, and since we’re not using PTEs but section mappings, the “PMD section table” is the final product of our mappings. - PTE:s, page table entries maps pages of RAM from physical to virtual memory. The initial boot translation table does not use these. We use sections.
Notice again: for classic ARM MMU PGD and PMD is the same thing. For LPAE it is two different things. This is sometimes referred to as “folding” PMD into PGD. Since in a way we are “folding” P4D and PUD as well, it becomes increasingly confusing.
If you work with virtual memory you will need to repeat the above from time to time. For our purposes of constructing the initial “page” table none of this really matters. What we are constructing is a list of 1MB sections mapping virtual memory to physical memory. We are not even dealing with pages at this point, so the entire “pages” terminology is mildly confusing.
The Binary Format of the Translation Table
Let use consider only the classic ARM MMU in the following.
From physical address 0x10004000 to 0x10007FFF we have 0x1000 (4096) section descriptors of 32 bits (4 bytes) each. How are these used?
The program counter and all CPU access will be working on virtual addresses after we turn on the MMU, so the translation will work this way: a virtual address is translated into a physical address before we access the bus.
The way the physical address is determined from the virtual address is as follows:
We take bits 31..20 of the virtual address and use this as index into the translation table to look up a 32bit section descriptor.
- Addresses
0x00000000-0x000FFFFF(the first 1MB) in virtual memory will be translated by the index at0x10004000-0x10004003, the first four bytes of the translation table, we call this index0. - Virtual address
0x00100000-0x001FFFFFwill be translated by index1at0x10004004-0x10004007, so index times four is the byte address of the descriptor. - …
- Virtual address
0xFFF00000-0xFFFFFFFFwill be translated by index0xFFFat0x10003FFC-0x10003FFF
Oh. Clever. 0x4000 (16KB) of memory exactly spans a 32bit i.e. 4GB memory space. So using this MMU table we can make a map of any virtual memory address 1MB chunk to any physical memory 1MB chunk. This is not a coincidence.
This means for example that for the kernel virtual base 0xC0000000 the index into the table will be 0xC0000000 >> 20 = 0xC00 and since the index need to be multiplied by 4 to get the actual byte index we get 0xC00 * 4 = 0x3000 so at physical address 0x10004000 + 0x3000 = 0x10007000 we find the section descriptor for the first 1MB of the kernelspace memory.
The 32-bit 1MB section descriptors we will use for our maps may have something like this format:

The MMU will look at bits 1,0 and determine that “10” means that this is a section mapping. We set up some default values for the other bits. Other than that we only really care about setting bits 31..20 to the right physical address and we have a section descriptor that will work. And this is what the code does.
For LPAE this story is a bit different: we use 64bit section descriptors (8 bytes) but at the same time, the sections are bigger: 2 MB instead of 1 MB, so in the end the translation table will have exactly the same size of 0x4000 bytes.
Identity mapping around MMU enablement code
First of all we create an identity mapping around the symbol __turn_mmu_on, meaning this snippet of code will be executing in memory that is mapped 1:1 between physical and virtual addresses. If the code is at 0x10009012 then the virtual address for this code will also be at 0x10009012. If we inspect the code we see that it is put into a separate section called .idmap.text. Creating a separate section means that this gets linked into a separate physical page with nothing else in it, so we map an entire 1MB section for just this code (maybe even two, if it happens to align just across a section boundary in memory), so that an identity mapping is done for this and this code only.
If we think about it this is usually cool, even if it spans say 2MB of memory: if we loaded the kernel at 0x10000000 as in our example, this code will be at something like 0x10000120 with an identity mapping at the same address this isn’t ever going to disturb the kernel at 0xC0000000 or even at 0x40000000 which is an extreme case of kernel memory split. If someone would start to place the start of physical memory at say 0xE0000000 we would be in serious trouble. Let’s pray that this never happens.
Mapping the rest
Next we create the physical-to virtual memory mapping for the main matter, starting at PHYS_OFFSET in the physical memory (the value we calculated in r8 in the section “Where Are We Executing”) and PAGE_OFFSET (a compile-time constant) in the virtual memory, then we move along one page at the time all the way until we reach the symbol _end in virtual memory which is set to the end of the .bss section of the kernel object itself.
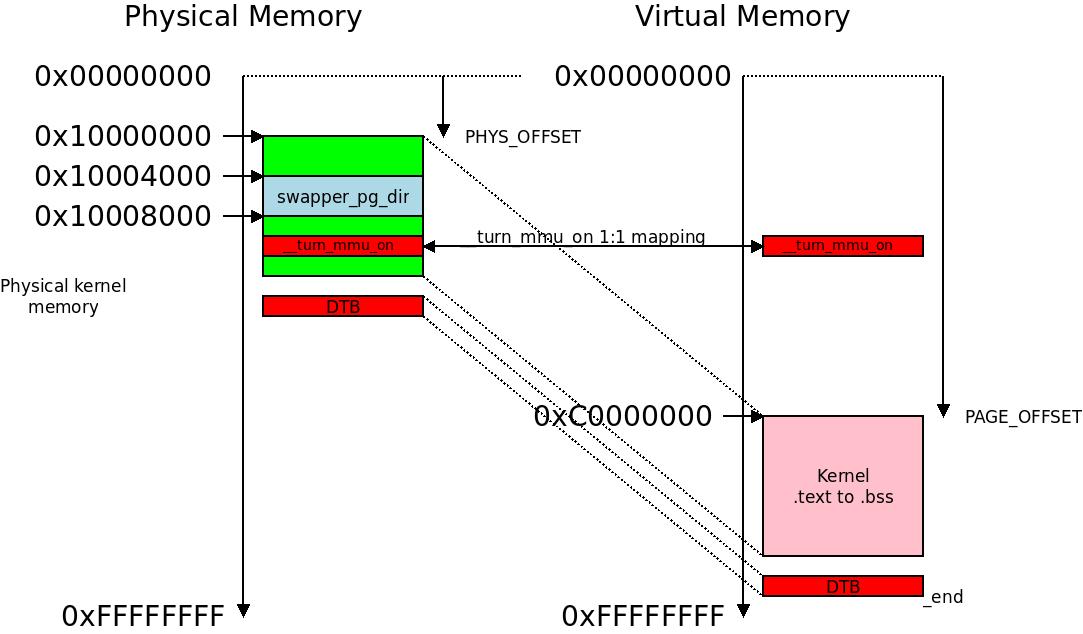 The initial page table swapper_pg_dir and the 1:1 mapped one-page-section __turn_mmu_on alongside the physical to virtual memory mapping at early boot. In this example we are not using LPAE so the initial page table is
The initial page table swapper_pg_dir and the 1:1 mapped one-page-section __turn_mmu_on alongside the physical to virtual memory mapping at early boot. In this example we are not using LPAE so the initial page table is -0x4000 from PHYS_OFFSET and memory ends at 0xFFFFFFFF.
BSS is an idiomatic name for the section at the very end of the binary kernel footprint in memory and this is where the C compiler assigns locations for all runtime variables. The addresses for this section are well defined, but there is no binary data for them: this memory has undefined contents, i.e. whatever was in it when we mapped it in.
It is worth studying this loop of assembly in detail to understand how the mapping code works:
ldr r7, [r10, #PROCINFO_MM_MMUFLAGS] @ mm_mmuflags
(...)
add r0, r4, #PAGE_OFFSET >> (SECTION_SHIFT - PMD_ORDER)
ldr r6, =(_end - 1)
orr r3, r8, r7
add r6, r4, r6, lsr #(SECTION_SHIFT - PMD_ORDER)
1: str r3, [r0], #1 << PMD_ORDER
add r3, r3, #1 << SECTION_SHIFT
cmp r0, r6
bls 1b
Let us take this step by step. We assume that we use non-LPAE classic ARM MMU in this example (you can convince yourself that the same holds for LPAE).
add r0, r4, #PAGE_OFFSET >> (SECTION_SHIFT - PMD_ORDER)
r4 contains the physical address of the page table (PGD or PMD) where we will set up our sections. (SECTION_SHIFT - PMD_ORDER) resolves to (20 – 2) = 18, so we take PAGE_OFFSET 0xC0000000 >> 18 = 0x3000 which is incidentally the absolute index into the translation table for 0xC0000000 as we saw earlier: aha. Well that makes sense since the index is 4 bytes. So whenever we see (SECTION_SHIFT - PMD_ORDER) that means “convert to absolute physical index into the translation table for this virtual address”, in our example case this will be 0x10003000.
So the first statement generates the physical address for the first 32bit section descriptor for the kernelspace memory in r0.
ldr r6, =(_end - 1)
r6 is obviously set to the very end of the kernelspace memory.
ldr r7, [r10, #PROCINFO_MM_MMUFLAGS] @ mm_mmuflags
(...)
orr r3, r8, r7
r8 contains the PHYS_OFFSET, in our case 0x10000000 (we count on bits 19..0 to be zero) and we OR that with r7 which represents what is jokingly indicated as “who cares” in the illustration above, is a per-CPU setting for the MMU flags defined for each CPU in arch/arm/mm/proc-*.S. Each of these files contain a special section named .proc.info.init and at index PROCINFO_MM_MMUFLAGS (which will be something like 0x08) there is the right value to OR into the section descriptor for the specific CPU we are using. The struct itself is named struct proc_info_list and can be found in arch/arm/include/asm/procinfo.h. Since assembly cannot really handle C structs some indexing trickery is used to get at this magic number.
So the section descriptor has a physical address in bits 31-20 and this value in r7 sets some more bits, like the two lowest, so that the MMU can handle this section descriptor right.
add r6, r4, r6, lsr #(SECTION_SHIFT - PMD_ORDER)
This will construct the absolute physical index address for the section descriptor for the last megabyte of memory that we map. We are not OR:in on the value from r7: we till just use this for a loop comparison, not really write it into the translation table, so it is not needed.
So now r0 is the physical address of the first section descriptor we are setting up and r6 is the physical address of the last section descriptor we will set up. We enter the loop:
1: str r3, [r0], #1 << PMD_ORDER
add r3, r3, #1 << SECTION_SHIFT
cmp r0, r6
bls 1b
This writes the first section descriptor into the MMU table, to the address in r0 which will start at 0x10003000 in our example. Then we post-increment the address in r0 with (1 << PMD_ORDER) which will be 4. Then we increase the descriptor physical address portion (bit 20 and upward) with 1 MB (1 << SECTION_SHIFT), check we we reached the last descriptor else loop to 1:.
This creates a virtual-to-physical map of the entire kernel including all segments and .bss in 1MB chunks.
Final mappings
Next we map some other things: we map the boot parameters specifically: this can be ATAGs or an appended device tree blob (DTB). ATAGs are usually the very first page of memory (at PHYS_OFFSET + 0x0100) While contemporary DTBs are usually somewhere below the kernel. You will notice that it would probably be unwise to place the DTB too far above the kernel, lest it will wrap around to lower addresses.
If we are debugging we also map the serial port specifically from/to predefined addresses in physical and virtual memory. This is done so that debugging can go on as we execute in virtual memory.
There is again an exception for “execute in place”: if we are executing from ROM we surely need to map the kernel from that specific address rather than the compile-time memory locations.
Jump to Virtual Memory
We are nearing the end of the procedure stext where we started executing the kernel.
First we call the per-cpu-type “procinit” function. This is some C/assembly clever low-level CPU management code that is collected per-CPU in arch/arm/mm/proc-*.S. For example most v7 CPUs have the initialization code in proc-v7.S and the ARM920 has its initialization code in proc-arm920.S. This will be useful later, but the “procinit” call is usually empty: only XScale really does anything here an it is about bugs pertaining to the boot loader initial state.
The way the procinit code returns is by the conventional ret lr which actually means that the value of the link register (lr) is assigned to the program counter (pc).
Before entering the procinit function we set lr to the physical address of label 1: which will make a relative branch to the symbol __enable_mmu. We also assign r13 the address of __mmap_switched, which is the compiletime-assigned, non-relative virtual address of the next execution point after the MMU has been enabled. We are nearing the end of relative code constructions.
We jump to __enable_mmu. r4 contains the address of the initial page table. We load this using a special CP15 instruction designed to load the page table pointer (in physical memory) into the MMU:
mcr p15, 0, r4, c2, c0, 0
Nothing happens so far. The page table address is set up in the MMU but it is not yet translating between physical and virtual addresses. Next we jump to __turn_mmu_on. This is where the magic happens. __turn_mmu_on as we said is cleverly compiled into the section .idmap.text which means it has the same address in physical and virtual memory. Next we enable the MMU:
mcr p15, 0, r0, c1, c0, 0 @ write control reg
mrc p15, 0, r3, c0, c0, 0 @ read id reg
BAM! The MMU is on. The next instruction (which is incidentally an instruction cache flush) will be executed from virtual memory. We don’t notice anything at first, but we are executing in virtual memory. When we return by jumping to the address passed in r13, we enter __mmap_switched at the virtual memory address of this function, somewhere below PAGE_OFFSET (typically 0xC0nnnnnn). We can now facilitate absolute addressing: the kernel is executing as intended.
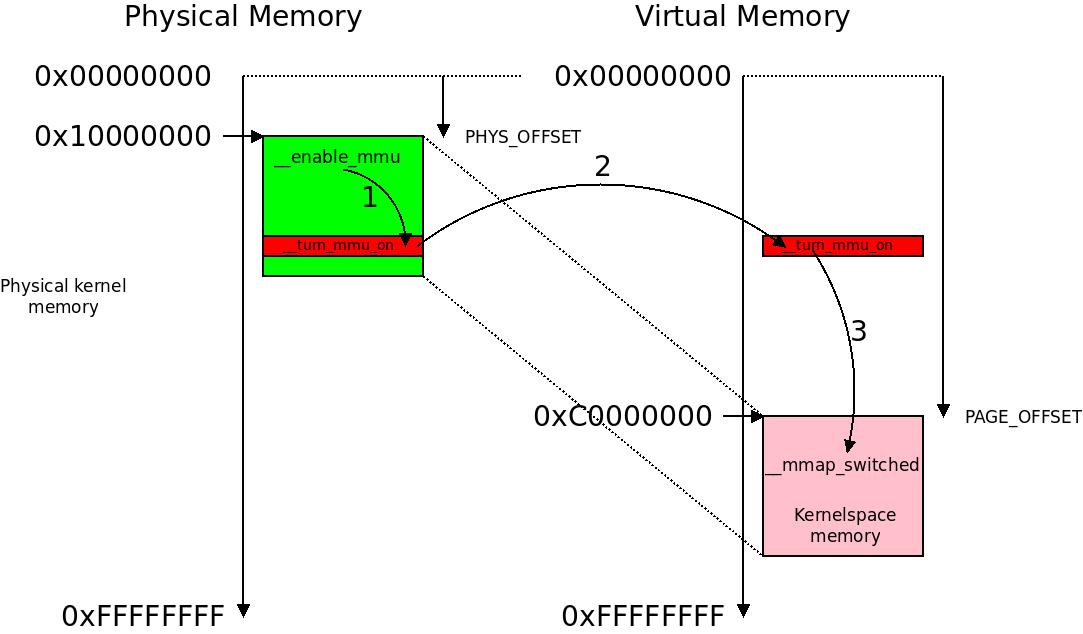 The little “dance” of the program counter as we switch execution from physical to virtual memory.
The little “dance” of the program counter as we switch execution from physical to virtual memory.
We have successfully bootstrapped the initial page table and we are now finally executing the kernel at the location the C compiler thought the kernel was going to execute at.
Now Let’s Get Serious
__mmap_switched can be found in the file arch/arm/kernel/head-common.S and will do a few specific things before we call the C runtime-enabled kernel proper.
First there is an exceptional clause, again for execute-in-place (XIP) kernels: while the .text segment of the kernel can certainly continue executing from ROM we cannot store any kind of variables from the .data segment there. So first this is set up by either just copying the segment to RAM or, using some fancy extra code, uncompressed to RAM (saving more silicon memory).
Next we zero out the .bss segment we got to know earlier: in the Linux kernel we rely on static variables being initialized to zero. Other C runtime environments may not do this, but when you run the Linux kernel you can rely on static variables being zero the first time you enter a function.
The machine has now switched to virtual memory and fully prepared the C runtime environment. We have also patched all cross-references between physical and virtual memory. We are ready to go.
So next we save the processor ID, machine type and ATAG or DTB pointer and branch to the symbol start_kernel(). This symbol resolves to an absolute address and is a C function found a bit down in the init/main.c file. It is fully generic: it is the same point that all other Linux architectures call, so we have now reached the level of generic kernel code written in C.
Let’s see where this is: to disassemble the kernel I just use the objdump tool from the toolchain and pipe it to less:
arm-linux-gnueabihf-objdump -D vmlinux |less
By searching for start_kernel by /start_kernel in less and skipping to the second hit we find:
c088c9d8 <start_kernel>:
c088c9d8: e92d4ff0 push {r4, r5, r6, r7, r8, r9, sl, fp, lr}
c088c9dc: e59f53e8 ldr r5, [pc, #1000] ; c088cdcc
c088c9e0: e59f03e8 ldr r0, [pc, #1000] ; c088cdd0
c088c9e4: e5953000 ldr r3, [r5]
c088c9e8: e24dd024 sub sp, sp, #36 ; 0x24
c088c9ec: e58d301c str r3, [sp, #28]
c088c9f0: ebde25e8 bl c0016198 <set_task_stack_end_magic>
Oh this is nice! We are executing C at address 0xC088C9D8, and we can now disassemble and debug the kernel as we like. When I have random crash dumps of the kernel I usually use exactly this method of combining objdump and less to disassemble the kernel and just search for the symbol that crashed me to figure out what is going on.
Another common trick among kernel developers is to enable low-level kernel debugging and putting a print at start_kernel() so that we know that we reach this point. My own favourite construction looks like this (I just insert these lines first in start_kernel()):
#if defined(CONFIG_ARM) && defined(CONFIG_DEBUG_LL)
{
extern void printascii(char *);
printascii("start_kernel\n");
}
#endif
As can be seen, getting low-level debug prints like this to work involves enabling CONFIG_DEBUG_LL, and then you should be able to see a life sign from the kernel before even the kernel banner is “Linux …” is printed.
This file and function should be well known to Linux kernel developers and a good thing to do on a boring day is to read through the code in this file, as this is how the generic parts of Linux bootstrap themselves.
The happiness of generic code will not last as we soon call setup_arch() and we are then back down in arch/arm again. We know for sure that our crude initial translation table will be replaced by a more elaborate proper translation table. There is not yet any such thing as a virtual-to-physical mapping of the userspace memory for example. But this is the topic of another discussion.