netdev in 2024
Developments in Linux kernel networking accomplished by many excellent developers and as remembered by Andew L, Eric D, Jakub K and Paolo A.
Another busy year has passed so let us punctuate the never ending stream of development with a retrospective of our accomplishments over the last 12 months. The previous, 2023 retrospective has covered changes from Linux v6.3 to v6.8, for 2024 we will cover Linux v6.9 to v6.13, one fewer, as Linux releases don’t align with calendar years. We will focus on the work happening directly on the netdev mailing list, having neither space nor expertise to do justice to developments within sub-subsystems like WiFi, Bluetooth, BPF etc.
Core
After months of work and many patch revisions we have finally merged support for Device Memory TCP, which allows TCP payloads to be placed directly in accelerator (GPU, TPU, etc.) or user space memory while still using the kernel stack for all protocol (header) processing (v6.12). The immediate motivation for this work is obviously the GenAI boom, but some of the components built to enable Device Memory TCP, for example queue control API (v6.10), should be more broadly applicable.
The second notable area of development was busy polling. Additions to the epoll API allow enabling and configuring network busy polling on a per-epoll-instance basis, making the feature far easier to deploy in a single application (v6.9). Even more significant was the addition of a NAPI suspension mechanism which allows for efficient and automatic switching between busy polling and IRQ-driven operation, as most real life applications are not constantly running under highest load (v6.12). Once again the work was preceded by paying off technical debt, it is now possible to configure individual NAPI instances rather than an entire network interface (v6.13).
Work on relieving the rtnl_lock pressure has continued throughout the year. The rtnl_lock is often mentioned as one of the biggest global locks in the kernel, as it protects all of the network configuration and state. The efforts can be divided into two broad categories – converting read operations to rely on RCU protection or other fine grained locking (v6.9, v6.10), and splitting the lock into per-network namespace locks (preparations for which started in v6.13).
Following discussions during last year’s LPC, the Real Time developers have contributed changes which make network processing more RT-friendly by allowing all packet processing to be executed in dedicated threads, instead of the softirq thread (v6.10). They also replaced implicit Bottom Half protection (the fact that code in BH context can’t be preempted, or migrated between CPUs) with explicit local locks (v6.11).
The routing stack has seen a number of small additions for ECMP forwarding, which underpins all modern datacenter network fabrics. ECMP routing can now maintain per-path statistics to allow detecting unbalanced use of paths (v6.9), and to reseed the hashing key to remediate the poor traffic distribution (v6.11). The weights used in ECMP’s consistent hashing have been widened from 8 bits to 16 bits (v6.12).
The ability to schedule sending packets at a particular time in the future has been extended to survive network namespace traversal (v6.9), and now supports using the TAI clock as a reference (v6.11). We also gained the ability to explicitly supply the timestamp ID via a cmsg during a sendmsg call (v6.13).
The number of “drop reasons”, helping to easily identify and trace packet loss in the stack is steadily increasing. Reason codes are now also provided when TCP RST packets are generated (v6.10).
Protocols
The protocol development wasn’t particularly active in 2024. As we close off the year 3 large protocol patch sets are being actively reviewed, but let us not steal 2025’s thunder, and limit ourselves to changes present in Linus’s tree by the end of 2024.
AF_UNIX socket family has a new garbage collection algorithm (v6.10). Since AF_UNIX supports file descriptor passing, sockets can hold references to each other, forming reference cycles etc. The old home grown algorithm which was a constant source of bugs has been replaced by one with more theoretical backing (Tarjan’s algorithm).
TCP SYN cookie generation and validation can now be performed from the TC subsystem hooks, enabling scaling out SYN flood handling across multiple machines (v6.9). User space can peek into data queued to a TCP socket at a specified offset (v6.10). It is also now possible to set min_rto for all new sockets using a sysctl, a patch which was reportedly maintained downstream by multiple hyperscalers for years (v6.11).
UDP segmentation now works even if the underlying device doesn’t support checksum offload, e.g. TUN/TAP (v6.11). A new hash table was added for connected UDP sockets (4-tuple based), significantly speeding-up connected socket lookup (v6.13).
MPTCP gained TCP_NOTSENT_LOWAT support (v6.9), and automatic tracking of destinations which blackhole MPTCP traffic (6.12).
IPsec stack now adheres to RFC 4301 when it comes to forwarding ICMP Error messages (v6.9).
Bonding driver supports independent control state machine in addition to the traditional coupled one, per IEEE 802.1AX-2008 5.4.15 (v6.9).
The GTP protocol gained IPv6 support (v6.10).
The High-availability Seamless Redundancy (HSR) protocol implementation gained the ability to work as a proxy node connecting non-HSR capable node to an HSR network (RedBOX mode) (v6.11).
The netconsole driver can attach arbitrary metadata to the log messages (v6.9).
The work on making Netlink easier to interface with in modern languages continued. The Netlink protocol descriptions in YAML can now express Netlink “polymorphism” (v6.9), i.e. a situation where parsing of one attribute depends on the value of another attribute (e.g. link type determines how link attributes are parsed). 7 new specs have been added, as well as a lot of small spec and code generation improvements. Sadly we still only have bindings/codegen for C, C++ and Python.
Device APIs
The biggest addition to the device-facing APIs in 2024 was the HW traffic shaping interface (v6.13). Over the years we have accumulated a plethora of single-vendor, single-use case rate control APIs. The new API promises to express most use cases, ultimately unifying the configuration from the user perspective. The immediate use for the new API is rate limiting traffic from a group of Tx queues. Somewhat related to this work was the revamp of the RSS context API which allows directing Rx traffic to a group of queues (v6.11, v6.12, v6.13). Together the HW rate limiting and RSS context APIs will hopefully allow container networking to leverage HW capabilities, without the need for complex full offloads.
A new API for reporting device statistics has been created (qstat) within the netdev netlink family (v6.9). It allows reporting more detailed driver-level stats than old interfaces, and breaking down the stats by Rx/Tx queue.
Packet processing in presence of TC classifier offloads has been sped up, the software processing is now fully skipped if all rules are installed in HW-only mode (v6.10).
Ethtool gained support for flashing firmware to SFP modules, and configuring thresholds used by automatic IRQ moderation (v6.11). The most significant change to ethtool APIs in 2024 was, however, the ability to interact with multiple PHYs for a single network interface (v6.12).
Work continues on adding configuration interfaces for supplying power over network wiring. Ethtool APIs have been extended with Power over Ethernet (PoE) support (v6.10). The APIs have been extended to allow reporting more information about the devices and failure reasons, as well as setting power limits (v6.11).
Configuration of Energy Efficient Ethernet is being reworked because the old API did not have enough bits to cover new link modes (2.5GE, 5GE), but we also used this as an opportunity to share more code between drivers (especially those using phylib), and encourage more uniform behavior (v6.9).
Testing
2024 was the year of improving our testing. We spent the previous winter break building out an automated testing system, and have been running the full suite of networking selftests on all code merged since January. The pre-merge tests are catching roughly one bug a day.
We added a handful of simple libraries and infrastructure for writing tests in Python, crucially allowing easy use of Netlink YAML bindings, and supporting tests for NIC drivers (v6.10).
Later in the year we added native integration of packetdrill tests into kselftest, and started importing batches of tests from the packetdrill library (v6.12).
Community and process
The maintainers, developers and community members have met at two conferences, the netdev track at Linux Plumbers and netconf in Vienna, and the netdev.conf 0x18 conference in Santa Clara.
We have removed the historic requirement for special formatting of multi-line comments in netdev (although it is still the preferred style), documented our guidance on the use of automatic resource cleanup, as well as sending cleanup patches (such as “fixing” checkpatch warnings in existing code).
In April, we announced the redefinition of the “Supported” status for NIC drivers, to try to nudge vendors towards more collaboration and better testing. Whether this change has the desired effect remains to be seen.
Last but not least Andrew Lunn and Simon Horman have joined the netdev maintainer group.
Full list of networking PRs this year (links)
6.9: https://lore.kernel.org/20240312042504.1835743-1-kuba@kernel.org 6.10: https://lore.kernel.org/20240514231155.1004295-1-kuba@kernel.org 6.11: https://lore.kernel.org/20240716152031.1288409-1-kuba@kernel.org 6.12: https://lore.kernel.org/20240915172730.2697972-1-kuba@kernel.org 6.13: https://lore.kernel.org/20241119161923.29062-1-pabeni@redhat.com
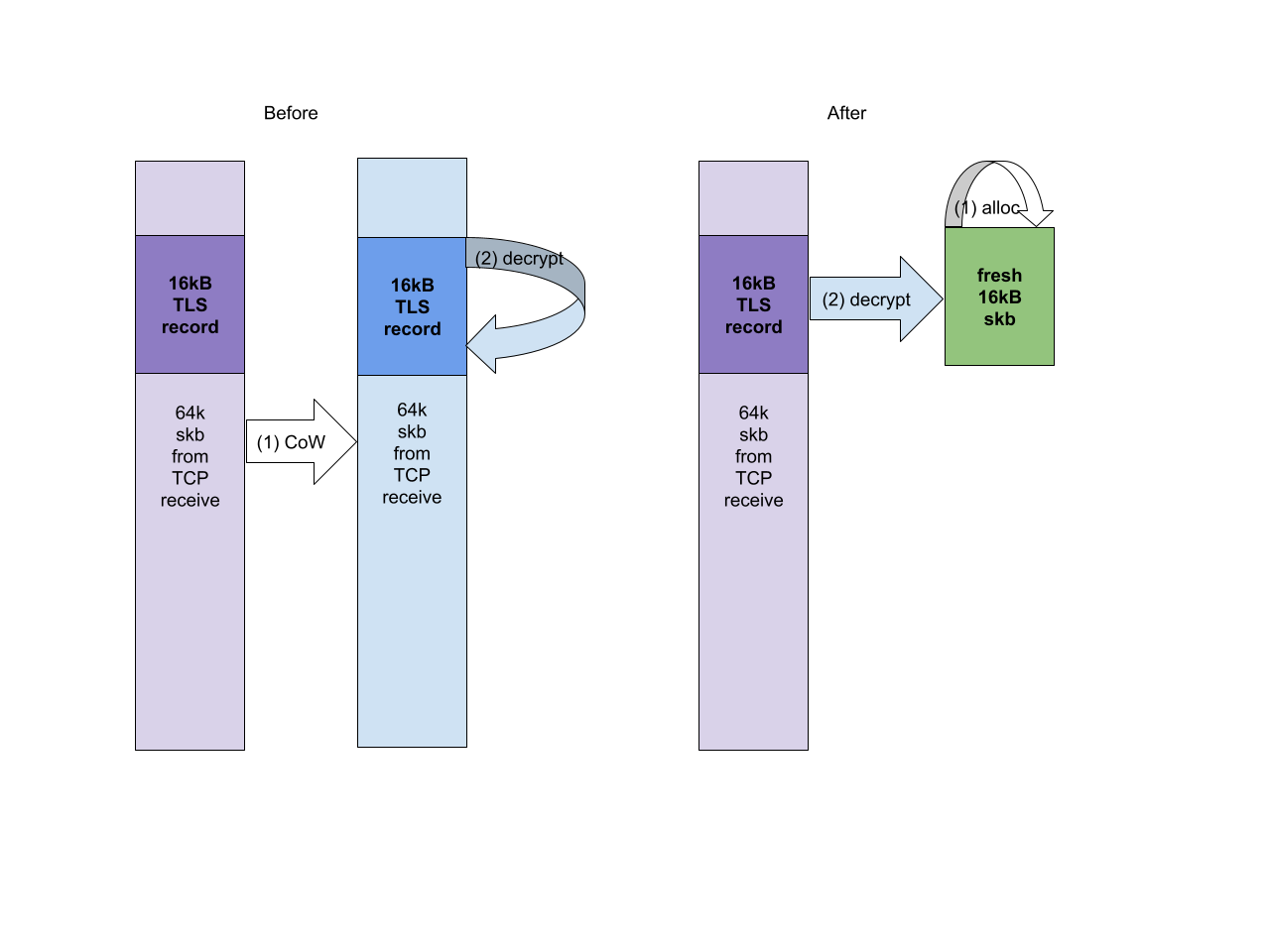 The possible solutions are quite obvious – either create a custom version of
The possible solutions are quite obvious – either create a custom version of 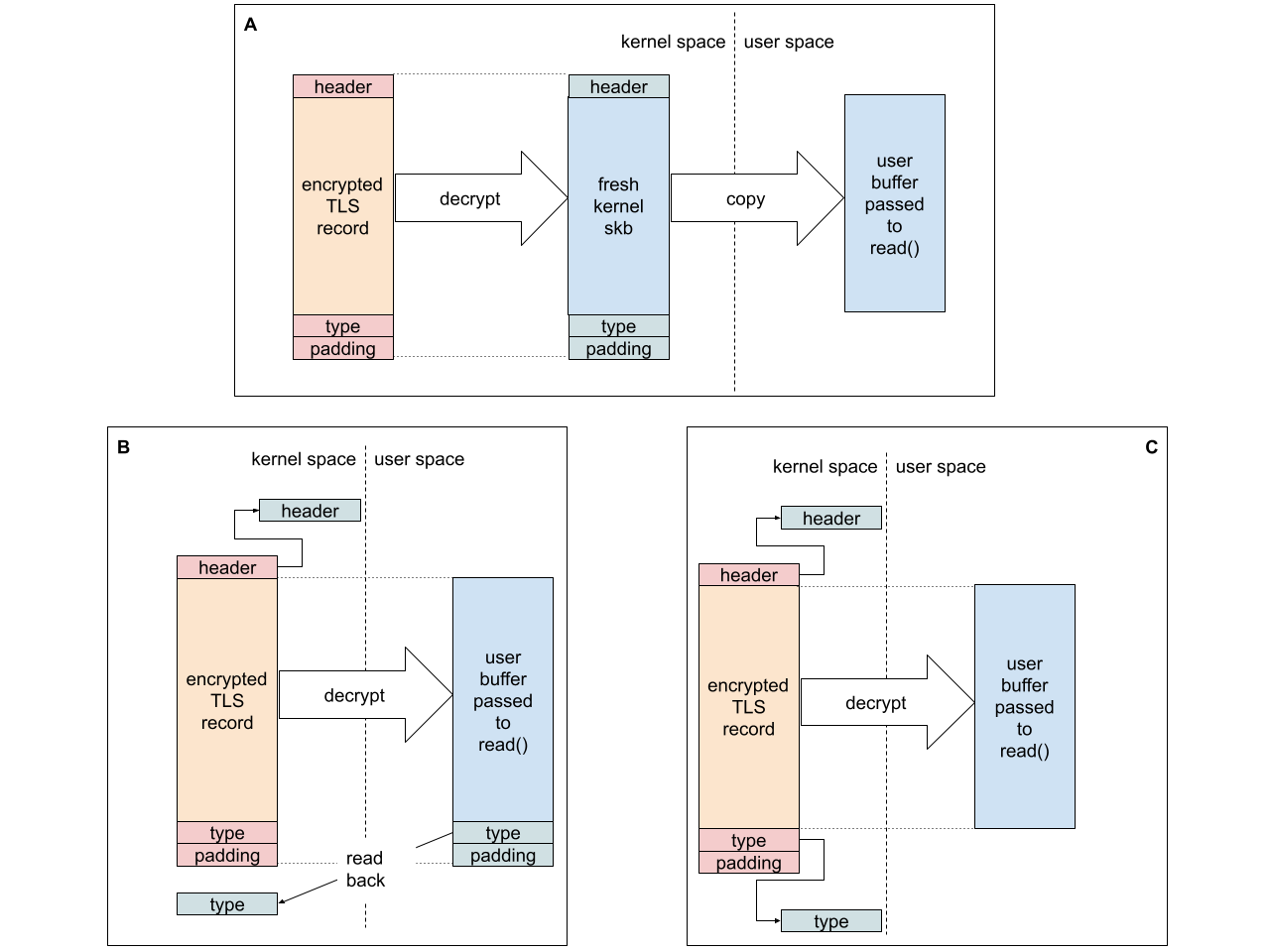 We can’t regain the full efficiency of TLS 1.2 because we don’t know the record type upfront. In practice, however, most of the records are data/application records (records carrying the application data rather than TLS control traffic like handshake messages or keys), so we can optimize for that case. We can optimistically decrypt to the user buffer, hoping the record contains data, and then check if we were right. Since decrypt to a user space buffer does not destroy the original encrypted record if we turn out to be wrong we can decrypting again, this time to a kernel skb (which we can then direct to the control message queue). Obviously this sort of optimization would not be acceptable in the Internet wilderness, as attackers could force us to waste time decrypting all records twice.
The real record type in TLS 1.3 is at the tail of the data. We must either trust that the application will not overwrite the record type after we place it in its buffer (B in the diagram below), or assume there will be no padding and use a kernel address as the destination of that chunk of data (C). Since record padding is also rare – I chose option (C). It improves the single stream performance by around 10%.
We can’t regain the full efficiency of TLS 1.2 because we don’t know the record type upfront. In practice, however, most of the records are data/application records (records carrying the application data rather than TLS control traffic like handshake messages or keys), so we can optimize for that case. We can optimistically decrypt to the user buffer, hoping the record contains data, and then check if we were right. Since decrypt to a user space buffer does not destroy the original encrypted record if we turn out to be wrong we can decrypting again, this time to a kernel skb (which we can then direct to the control message queue). Obviously this sort of optimization would not be acceptable in the Internet wilderness, as attackers could force us to waste time decrypting all records twice.
The real record type in TLS 1.3 is at the tail of the data. We must either trust that the application will not overwrite the record type after we place it in its buffer (B in the diagram below), or assume there will be no padding and use a kernel address as the destination of that chunk of data (C). Since record padding is also rare – I chose option (C). It improves the single stream performance by around 10%.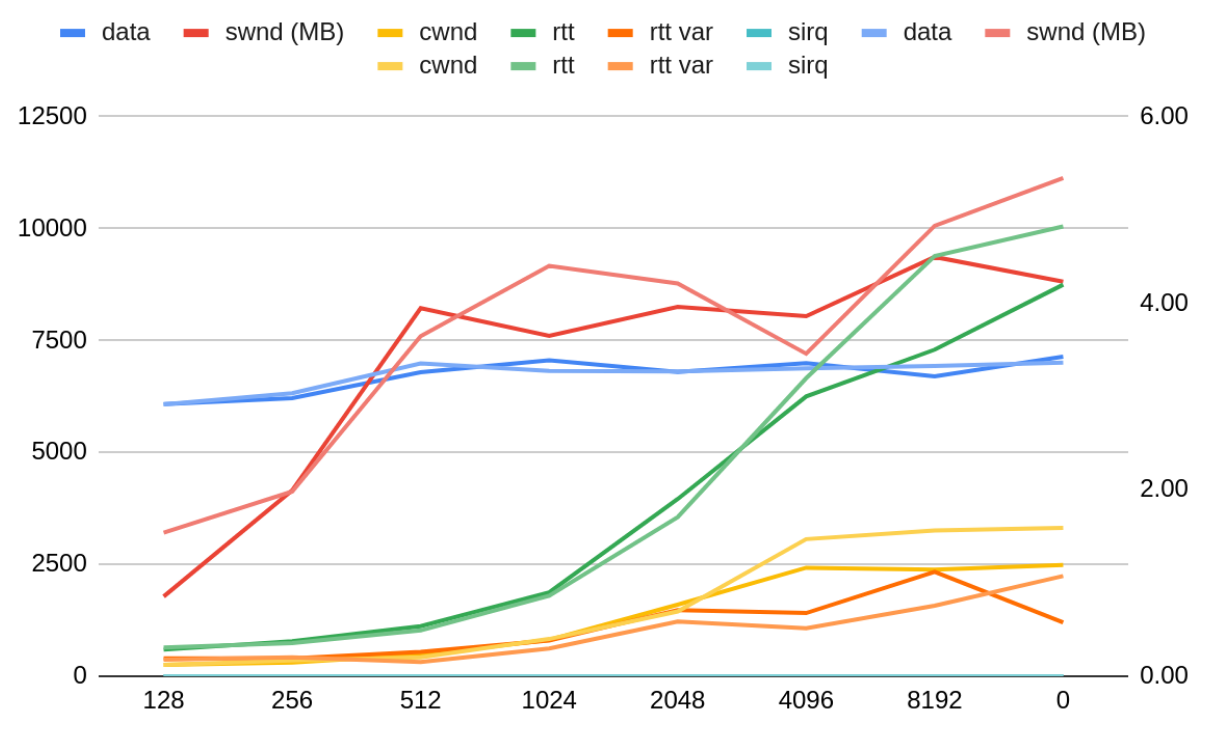 The TCP-perceived RTT of the connection grows the longer TLS hogs the socket lock without letting TCP process the ingress backlog. TCP responds by growing the congestion window.
Delaying the TCP processing will prevent TCP from responding to network congestion effectively, therefore I decided to be conservative and use 128kB as the TCP processing threshold.
Processing the incoming packets has the additional benefit of TLS being able to consume the data as it comes in from the NIC. Previously TLS had access to the data already processed by TCP when the read operation began. Any packets coming in from the NIC while TLS was decrypting would be backlogged at TCP input. On the way to user space TLS would release the socket lock, allowing the TCP backlog processing to kick in. TCP processing would schedule a TLS worker. TLS worker would tell the application there is more data.
The TCP-perceived RTT of the connection grows the longer TLS hogs the socket lock without letting TCP process the ingress backlog. TCP responds by growing the congestion window.
Delaying the TCP processing will prevent TCP from responding to network congestion effectively, therefore I decided to be conservative and use 128kB as the TCP processing threshold.
Processing the incoming packets has the additional benefit of TLS being able to consume the data as it comes in from the NIC. Previously TLS had access to the data already processed by TCP when the read operation began. Any packets coming in from the NIC while TLS was decrypting would be backlogged at TCP input. On the way to user space TLS would release the socket lock, allowing the TCP backlog processing to kick in. TCP processing would schedule a TLS worker. TLS worker would tell the application there is more data.