TLS 1.3 Rx improvements in Linux 5.20
Kernel TLS implements the record encapsulation and cryptography of the TLS protocol. There are four areas where implementing (a portion of) TLS in the kernel helps:
- enabling seamless acceleration (NIC or crypto accelerator offload)
- enabling sendfile on encrypted connections
- saving extra data copies (data can be encrypted as it is copied into the kernel)
- enabling the use of TLS on kernel sockets (nbd, NFS etc.)
Kernel TLS handles only data records turning them into a cleartext data stream, all the control records (TLS handshake etc.) get sent to the application via a side channel for user space (OpenSSL or such) to process.
The first implementation of kTLS was designed in the good old days of TLS 1.2. When TLS 1.3 came into the picture the interest in kTLS had slightly diminished and the implementation, although functional, was rather simple and did not retain all the benefits. This post covers developments in the Linux 5.20 implementation of TLS which claws back the performance lost moving to TLS 1.3.
One of the features we lost in TLS 1.3 was the ability to decrypt data as it was copied into the user buffer during read. TLS 1.3 hides the true type of the record. Recall that kTLS wants to punt control records to a different path than data records. TLS 1.3 always populates the TLS header with application_data as the record type and the real record type is appended at the end, before record padding. This means that the data has to be decrypted for the true record type to be known.
Problem 1 – CoW on big GRO segments is inefficient
kTLS was made to dutifully decrypt the TLS 1.3 records first before copying the data to user space. Modern CPUs are relatively good at copying data, so the copy is not a huge problem in itself. What’s more problematic is how the kTLS code went about performing the copy.
The data queued on TCP sockets is considered read-only by the kernel. The pages data sits in may have been zero-copy-sent and for example belong to a file. kTLS tried to decrypt “in place” because it didn’t know how to deal with separate input/output skbs. To decrypt “in place” it calls skb_cow_data(). As the name suggests this function makes a copy of the memory underlying an skb, to make it safe for writing. This function, however, is intended to be run on MTU-sized skbs (individual IP packets), not skbs from the TCP receive queue. The skbs from the receive queue can be much larger than a single TLS record (16kB). As a result TLS would CoW a 64kB skb 4 times to extract the 4 records inside it. Even worse if we consider that the last record will likely straddle skbs so we need to CoW two 64kB skbs to decrypt it “in place”. The diagram below visualizes the problem and the solution.
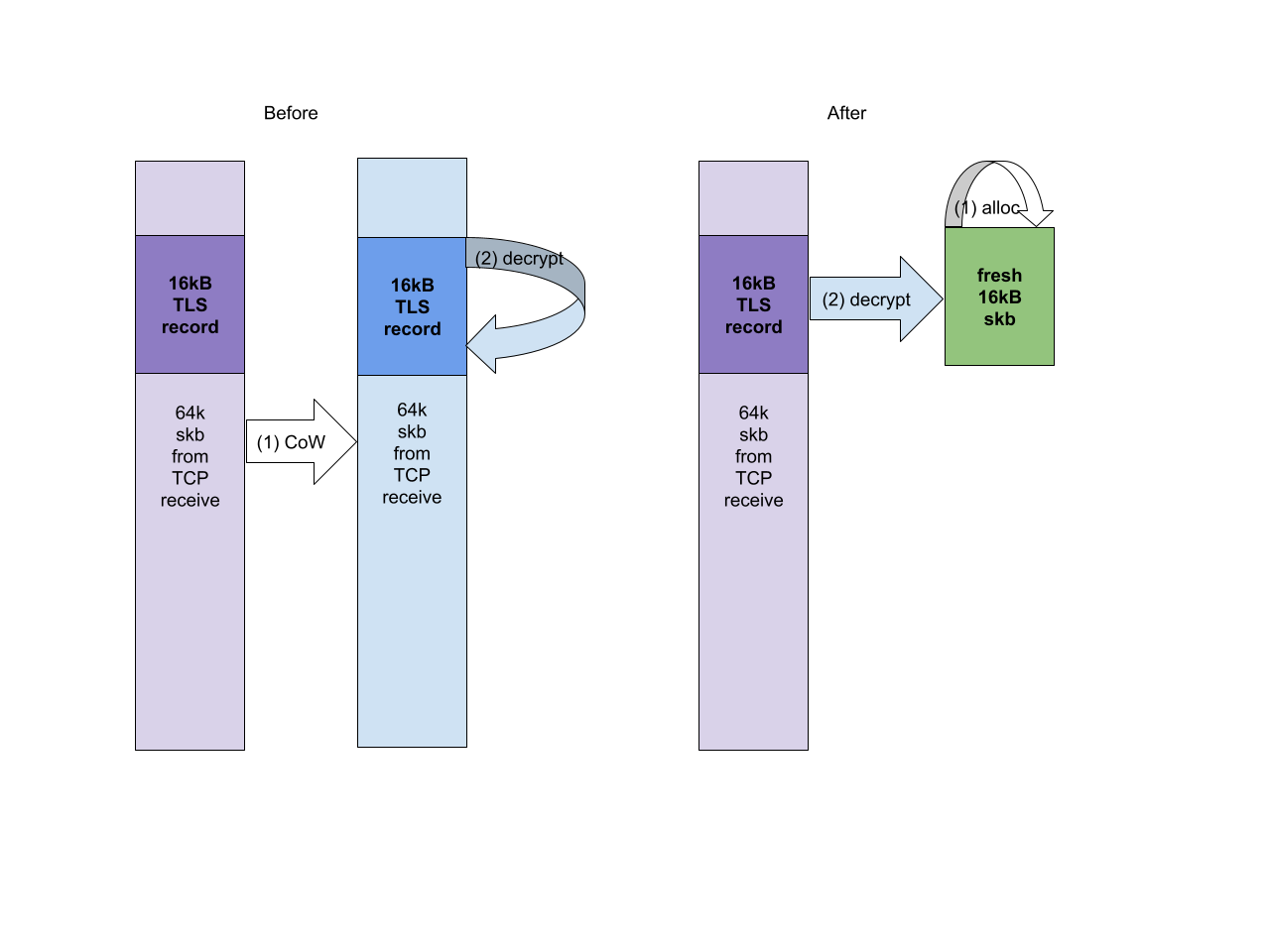 The possible solutions are quite obvious – either create a custom version of
The possible solutions are quite obvious – either create a custom version of skb_cow_data() or teach TLS to deal with different input and output skbs. I opted for the latter (due to further optimizations it enables). Now we use a fresh buffer for the decrypted data and there is no need to CoW the big skbs TCP produces. This fix alone results in ~25-45% performance improvement (depending on the exact CPU SKU and available memory bandwidth). A jump in performance from abysmal to comparable with the user space OpenSSL.
Problem 2 – direct decrypt
Removing pointless copies is all well and good, but as mentioned we also lost the ability to decrypt directly to the user space buffer. We still need to copy the data to user space after it has been decrypted (A in the diagram below, here showing just a single record not full skb).
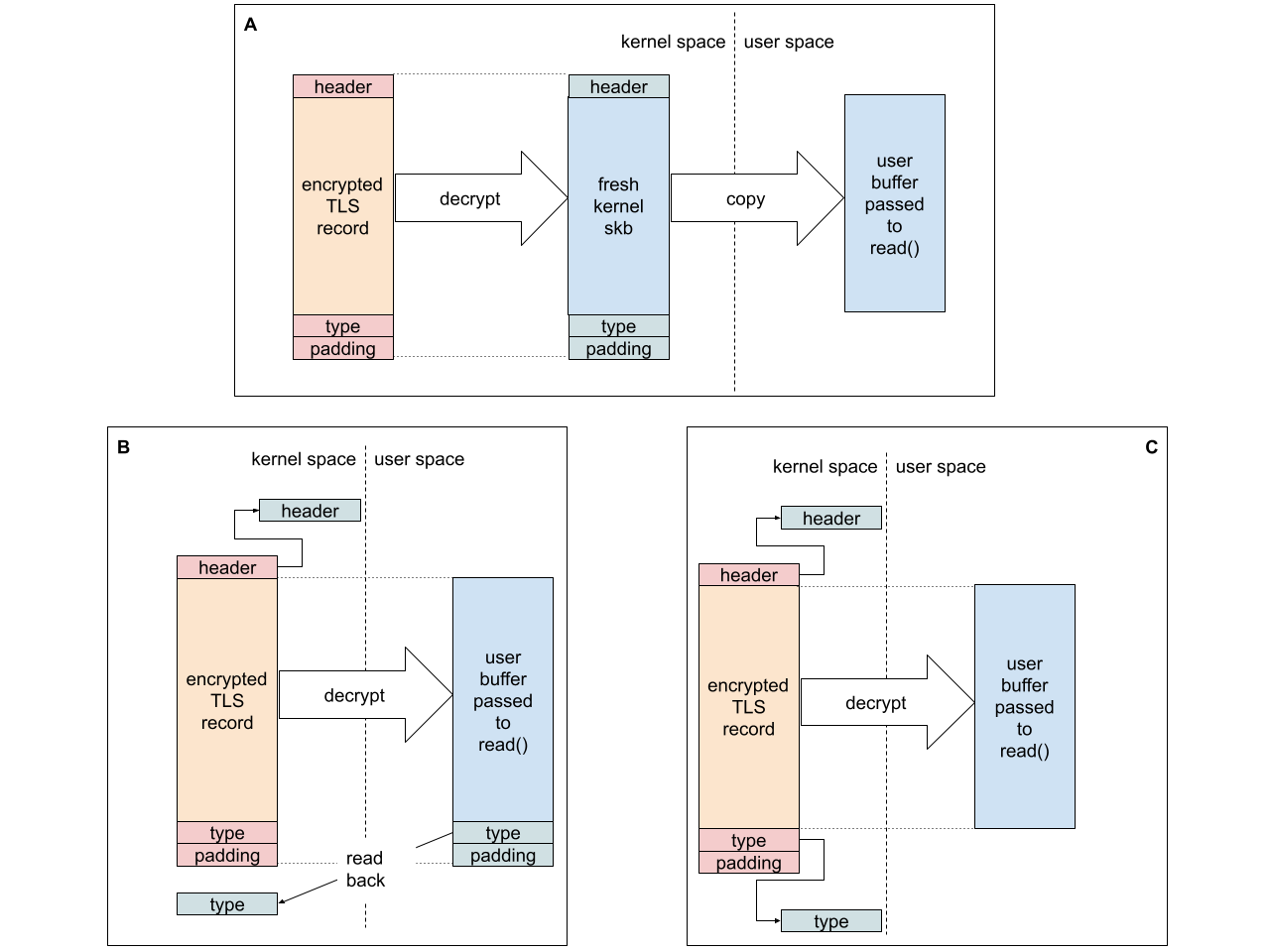 We can’t regain the full efficiency of TLS 1.2 because we don’t know the record type upfront. In practice, however, most of the records are data/application records (records carrying the application data rather than TLS control traffic like handshake messages or keys), so we can optimize for that case. We can optimistically decrypt to the user buffer, hoping the record contains data, and then check if we were right. Since decrypt to a user space buffer does not destroy the original encrypted record if we turn out to be wrong we can decrypting again, this time to a kernel skb (which we can then direct to the control message queue). Obviously this sort of optimization would not be acceptable in the Internet wilderness, as attackers could force us to waste time decrypting all records twice.
The real record type in TLS 1.3 is at the tail of the data. We must either trust that the application will not overwrite the record type after we place it in its buffer (B in the diagram below), or assume there will be no padding and use a kernel address as the destination of that chunk of data (C). Since record padding is also rare – I chose option (C). It improves the single stream performance by around 10%.
We can’t regain the full efficiency of TLS 1.2 because we don’t know the record type upfront. In practice, however, most of the records are data/application records (records carrying the application data rather than TLS control traffic like handshake messages or keys), so we can optimize for that case. We can optimistically decrypt to the user buffer, hoping the record contains data, and then check if we were right. Since decrypt to a user space buffer does not destroy the original encrypted record if we turn out to be wrong we can decrypting again, this time to a kernel skb (which we can then direct to the control message queue). Obviously this sort of optimization would not be acceptable in the Internet wilderness, as attackers could force us to waste time decrypting all records twice.
The real record type in TLS 1.3 is at the tail of the data. We must either trust that the application will not overwrite the record type after we place it in its buffer (B in the diagram below), or assume there will be no padding and use a kernel address as the destination of that chunk of data (C). Since record padding is also rare – I chose option (C). It improves the single stream performance by around 10%.
Problem 3 – latency
Applications tests have also showed that kTLS performs much worse than user space TLS in terms of the p99 RPC response latency. This is due to the fact that kTLS holds the socket lock for very long periods of time, preventing TCP from processing incoming packets. Inserting periodic TCP processing points into the kTLS code fixes the problem. The following graph shows the relationship between the TCP processing frequency (on the x axis in kB of consumed data, 0 = inf), throughput of a single TLS flow (“data”) and TCP socket state.
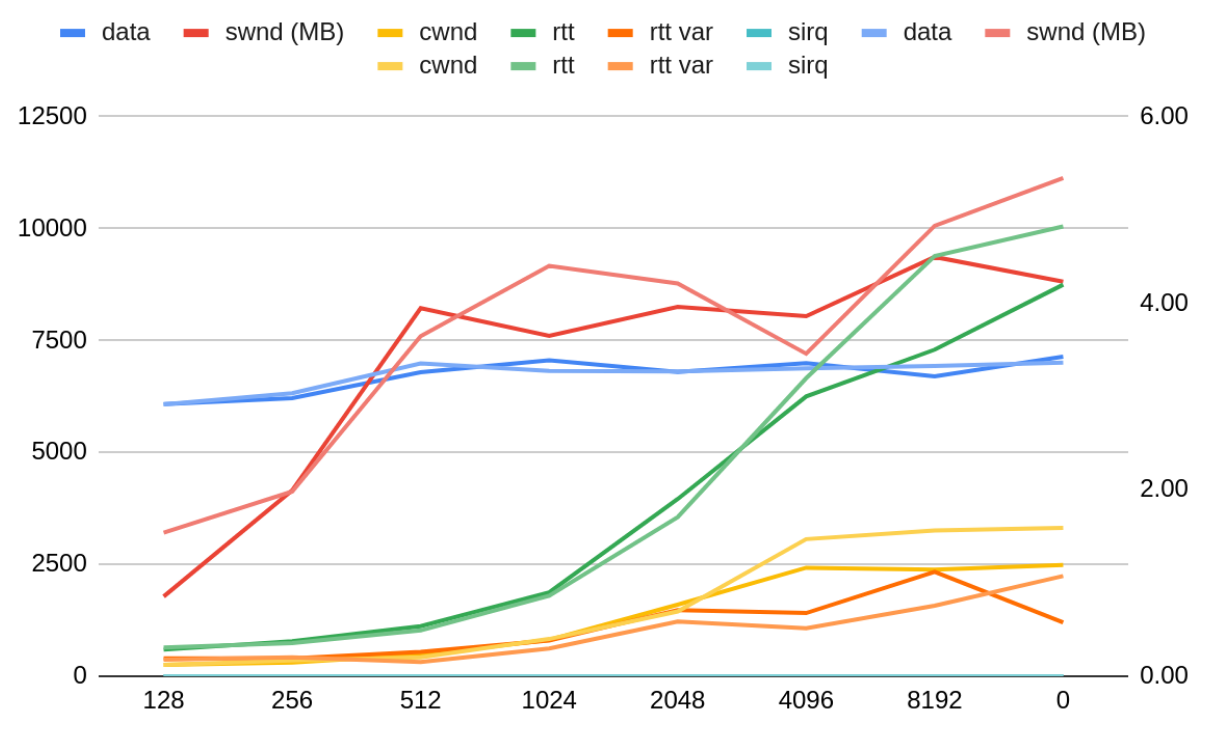 The TCP-perceived RTT of the connection grows the longer TLS hogs the socket lock without letting TCP process the ingress backlog. TCP responds by growing the congestion window.
Delaying the TCP processing will prevent TCP from responding to network congestion effectively, therefore I decided to be conservative and use 128kB as the TCP processing threshold.
Processing the incoming packets has the additional benefit of TLS being able to consume the data as it comes in from the NIC. Previously TLS had access to the data already processed by TCP when the read operation began. Any packets coming in from the NIC while TLS was decrypting would be backlogged at TCP input. On the way to user space TLS would release the socket lock, allowing the TCP backlog processing to kick in. TCP processing would schedule a TLS worker. TLS worker would tell the application there is more data.
The TCP-perceived RTT of the connection grows the longer TLS hogs the socket lock without letting TCP process the ingress backlog. TCP responds by growing the congestion window.
Delaying the TCP processing will prevent TCP from responding to network congestion effectively, therefore I decided to be conservative and use 128kB as the TCP processing threshold.
Processing the incoming packets has the additional benefit of TLS being able to consume the data as it comes in from the NIC. Previously TLS had access to the data already processed by TCP when the read operation began. Any packets coming in from the NIC while TLS was decrypting would be backlogged at TCP input. On the way to user space TLS would release the socket lock, allowing the TCP backlog processing to kick in. TCP processing would schedule a TLS worker. TLS worker would tell the application there is more data.