The offlineimap woes
A long term goal I've had for a while now was finding a reasonable replacement for offlineimap to get all my email for my development purposes. I knew offlineimap kept dying on me with out of memory (OOM) errors however it was not clear how bad the issue was. It was also not clear what I'd replace it with until now. At least for now... I've replaced offlineimap with mbsync. Below are some details comparing both, with shiny graphs of system utilization on both, I'll provide my recipes for fetching gmail nested labels over IMAP, glance over my systemd user unit files and explain why I use them, and hint what I'm asking Santa for in the future.
System setup when home is $HOME
I used to host my mail fetching system at home, however, $HOME can get complicated if you travel often, and so for more flexibility I rely now on a digital ocean droplet with a small dedicated volume pool for storage for mail. This lets me do away with the stupid host whenever I'm tired of it, and lets me collect nice system utilization graphs without much effort.
Graphing use on offlineimap
Every now and then I'd check my logs and see how offlineimap tends to run out of memory, and would tend to barf. A temporary solution I figure would work was to disable autorefresh, and instead run offlineimap once in a controlled timely loop using systemd unit timers. That solution didn't help in the end. I finally had a bit of time to check my logs carefully and also check system utilization graphs on the sytem over time and to my surprise offlineimap was running out of memory every single damn time. Here's what I saw from results of running offlineimap for a full month:
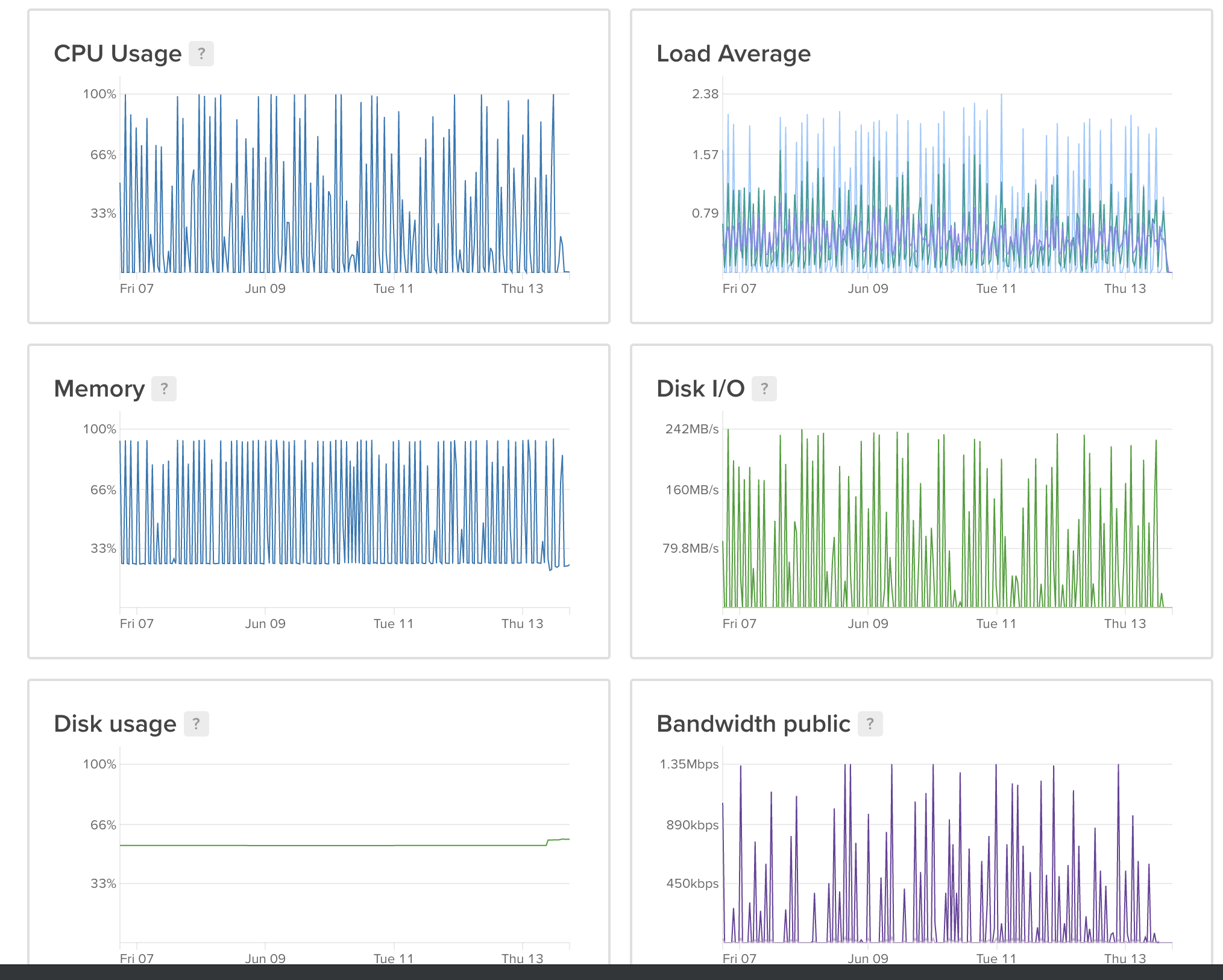
Those spikes are a bit concerning, it's likely the system running out of memory. But let's zoom in to see how often with an hourly graph:

Pretty much, I was OOM'ing every single damn time! The lull you see towards the end was me just getting fed up and killing offlineimap until I found a replacement.
The OOM risks
Running out of memory every now and then is one thing, but every single time is just insanity. A system always running low on memory while doing writes is an effective way to stress test a kernel, and if the stars align against you, you might even end up with a corrupted filesystem. Fortunately this puny single threaded application is simple enough so I didn't run into that issue. But it was a risk.
mbsync
mbsync is written in C, actively maintained and has mutt code pedigree. Need I say more? Hell, I'm only sad it took me so long to find out about it. mbsync works with idea of channels, for each it would have a master and local store. The master is where we fetch data from, and the local where we stash things locally.
But in reading its documentation it was not exactly clear how I'd use it for my development purpose to fetch email off of my gmail where I used nested labels for different public mailing lists.
The documentation was also not clear on what to do when migrating and keeping old files.
mbsync migration
Yes in theory you could keep the old IMAP folder, but in practice I ran into a lot of issues. So much so, my solution to the problem was:
$ rm -rf Mail/
And just start fresh... Afraid to make the jump due to the amount of time it may take to sync one of your precious labels? Well, evaluate my different timer solution below.
mbsync for nested gmail labels
Here's what I ended up with. It demos getting mail to say my linux-kernel/linux-xfs and linux-kernel/linux-fsdevel mailing lists, and includes some empirical throttling to ensure you don't get punted by gmail for going over some sort of usage quota they've concocted for an IMAP connection.
# A gmail example
#
# First generic defaults
# This example was updated on 2021-05-27 to account
# for the isync rename of Master/Slave for Far/Near
Create Near
SyncState *
IMAPAccount gmail
SSLType IMAPS
Host imap.gmail.com
User user@gmail.com
# Must be an application specific password, otherwise google will deny access.
Pass example
# Throttle mbsync so we don't go over gmail's quota: OVERQUOTA error would
# eventually be returned otherwise. For more details see:
# https://sourceforge.net/p/isync/mailman/message/35458365/
# PipelineDepth 50
MaildirStore gmail-local
# The trailing "/" is important
Path ~/Mail/
Inbox ~/Mail/Inbox
Subfolders Verbatim
IMAPStore gmail-remote
Account gmail
# emails sent directly to my kernel.org address
# are stored in my gmail label "korg"
Channel korg
Far :gmail-remote:"korg"
Near :gmail-local:korg
# An example of nested labels on gmail, useful for large projects with
# many mailing lists. We have to flatten out the structure locally.
Channel linux-xfs
Far :gmail-remote:"linux-kernel/linux-xfs"
Near :gmail-local:linux-kernel.linux-xfs
Channel linux-fsdevel
Far :gmail-remote:"linux-kernel/linux-fsdevel"
Near :gmail-local:linux-kernel.linux-fsdevel
# Get all the gmail channels together into a group.
Group googlemail
Channel korg
Channel linux-xfs
Channel linux-fsdevel
mbsync systemd unit files
Now, some of these mailing lists (channels in mbsync lingo) have heavy traffic, and I don't need to be fetching email off of them that often. I also have a channel dedicated solely for emails sent directly to me, those I want right away. But also... since I'm starting fresh, if I ran mbsync to fetch all my email it would mean that at one point mbsync would stall for any large label I'd have. I'd have to wait for those big labels before getting new email for smaller labels. For this reason, ideally I 'd want to actually call mbsync at different intervals depending on the mailing list / mbsync channel. Fortunately mbsync locks per target local directory, and so the only missing piece was a way to configure timers / calls for mbsync in such a way I could still journal calls / issues.
I ended up writing a systemd timer and a service unit file per mailing list. The nice thing about this, in favor over using good 'ol cron, is OnUnitInactiveSec=4m, for instance will call mbsync 4 minutes after it last finished. I also end up with a central place to collect logs:
journalctl --user
Or if I want to monitor:
journalctl --user -f
For my korg label, patches / rants sent directly to me, I want to fetch mail every minute:
$ cat .config/systemd/user/mbsync-korg.timer
[Unit]
Description=mbsync query timer [0000-korg]
ConditionPathExists=%h/.mbsyncrc
[Timer]
OnBootSec=1m
OnUnitInactiveSec=1m
[Install]
WantedBy=default.target
$ cat .config/systemd/user/mbsync-korg.service
[Unit]
Description=mbsync service [korg]
Documentation=man:mbsync(1)
ConditionPathExists=%h/.mbsyncrc
[Service]
Type=oneshot
ExecStart=/usr/local/bin/mbsync 0000-korg
[Install]
WantedBy=mail.target
However for my linux-fsdevel... I could wait at least 30 minutes for a refresh:
$ cat .config/systemd/user/mbsync-linux-fsdevel.timer
[Unit]
Description=mbsync query timer [linux-fsdevel]
ConditionPathExists=%h/.mbsyncrc
[Timer]
OnBootSec=5m
OnUnitInactiveSec=30m
[Install]
WantedBy=default.target
And the service unit:
$ cat .config/systemd/user/mbsync-linux-fsdevel.service
[Unit]
Description=mbsync service [linux-fsdevel]
Documentation=man:mbsync(1)
ConditionPathExists=%h/.mbsyncrc
[Service]
Type=oneshot
ExecStart=/usr/local/bin/mbsync linux-fsdevel
[Install]
WantedBy=mail.target
Enabling and starting systemd user unit files
To enable these unit files I just run for each, for instance for linux-fsdevel:
# The first command is now required on more recent versions
# of systemd. Only older versions of systemd
# you just need to enable the timer and start it
systemctl --user enable mbsync-linux-fsdevel.service
systemctl --user enable mbsync-linux-fsdevel.timer
systemctl --user start mbsync-linux-fsdevel.timer
Graphing mbsync
So... how did it do?
I currently have enabled 5 mbsync channels, all fetching my email in the background for me. And not a single one goes on puking with OOM. Here's what life is looking like now:
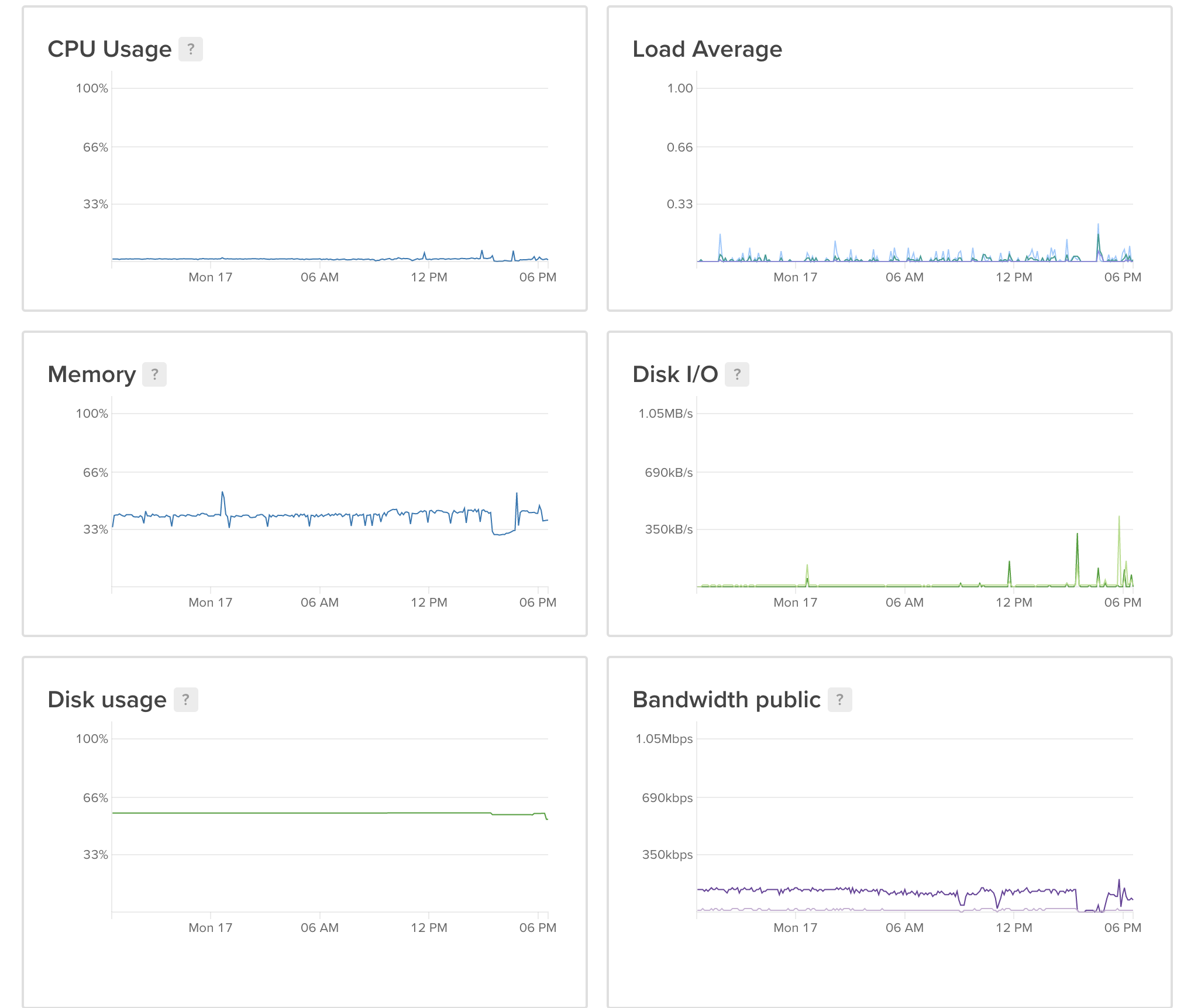
Peachy.
Long term ideals
IMAP does the job for email, it just seems utterly stupid for public mailing lists and I figure we can do much better. This is specially true in light of the fact of how much simpler it is for me to follow public code Vs public email threads these days. Keep in mind how much more complicated code management is over the goal of just wanting to get a simple stupid email Message ID onto my local Maildir directory. I really had my hopes on public-inbox but after looking into it, it seems clear now that its main objectives are for archiving — not local storage / MUA use. For details refer to this linux-kernel discussion on public-inbox
with a MUA focus.
If the issue with using public-inbox for local MUA usage was that archive was too big... it seems sensible to me to evaluate trying an even smaller epoch size, and default clients to fetch only one epoch, the latest one. That alone wouldn't solve the issue though. How data files are stored on Maildir makes using git almost incompatible. A proper evaluation of using mbox would be in order.
The social lubricant is out on the idea though, and I'm in hopes a proper simple git Mail solution is bound to find us soon for public emails.